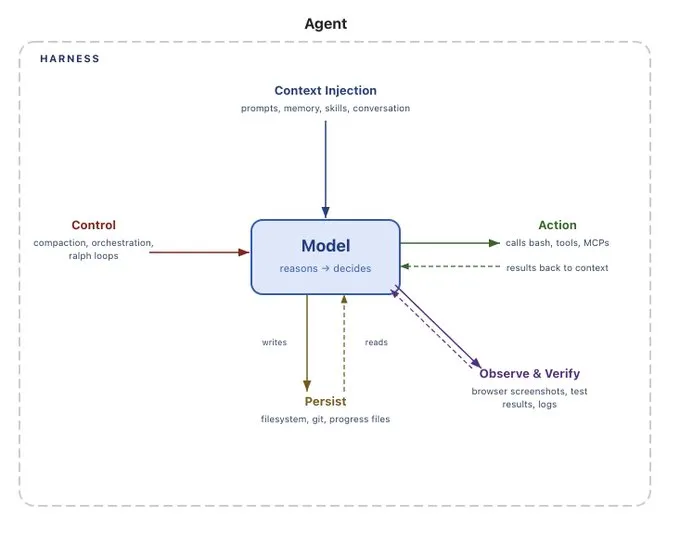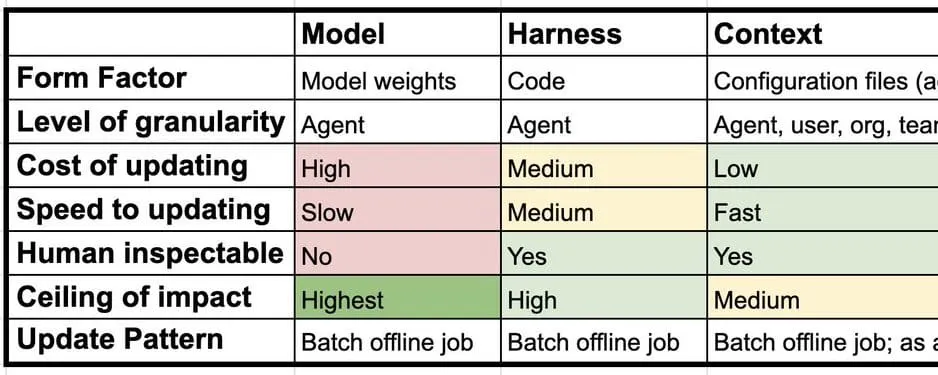
Most teams start thinking about agent observability as a debugging tool. Something went wrong, so you open the trace, inspect the steps, and figure out where the agent made a bad decision.
That is useful. But it is too narrow.
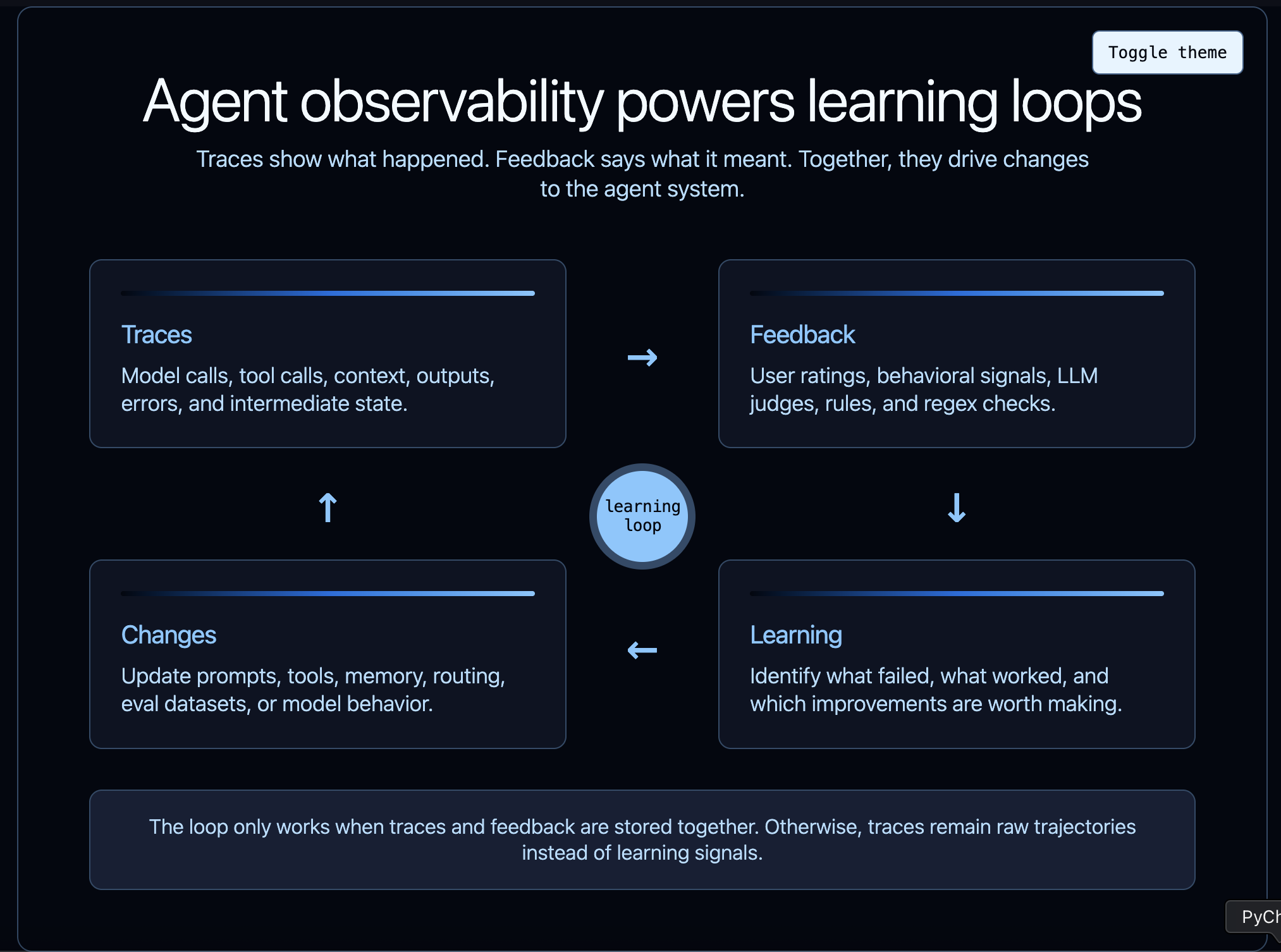
The deeper role of agent observability is to power learning. But traces alone do not create that loop. You also need feedback: signals that tell you whether the agent’s behavior was useful, accepted, rejected, inefficient, risky, or wrong.
Not just learning in the model-training sense, but learning across the whole agent system: what the model should do, how the harness should guide it, what context it needs, which failure modes are recurring, and which behaviors are actually working for users.
Traces are not just records of what happened, and feedback is not just a rating at the end. Together, they are the raw material for improving the system.
Learning happens at multiple levels
There are several ways that agentic systems can "learn" and improve over time. We wrote about them here:
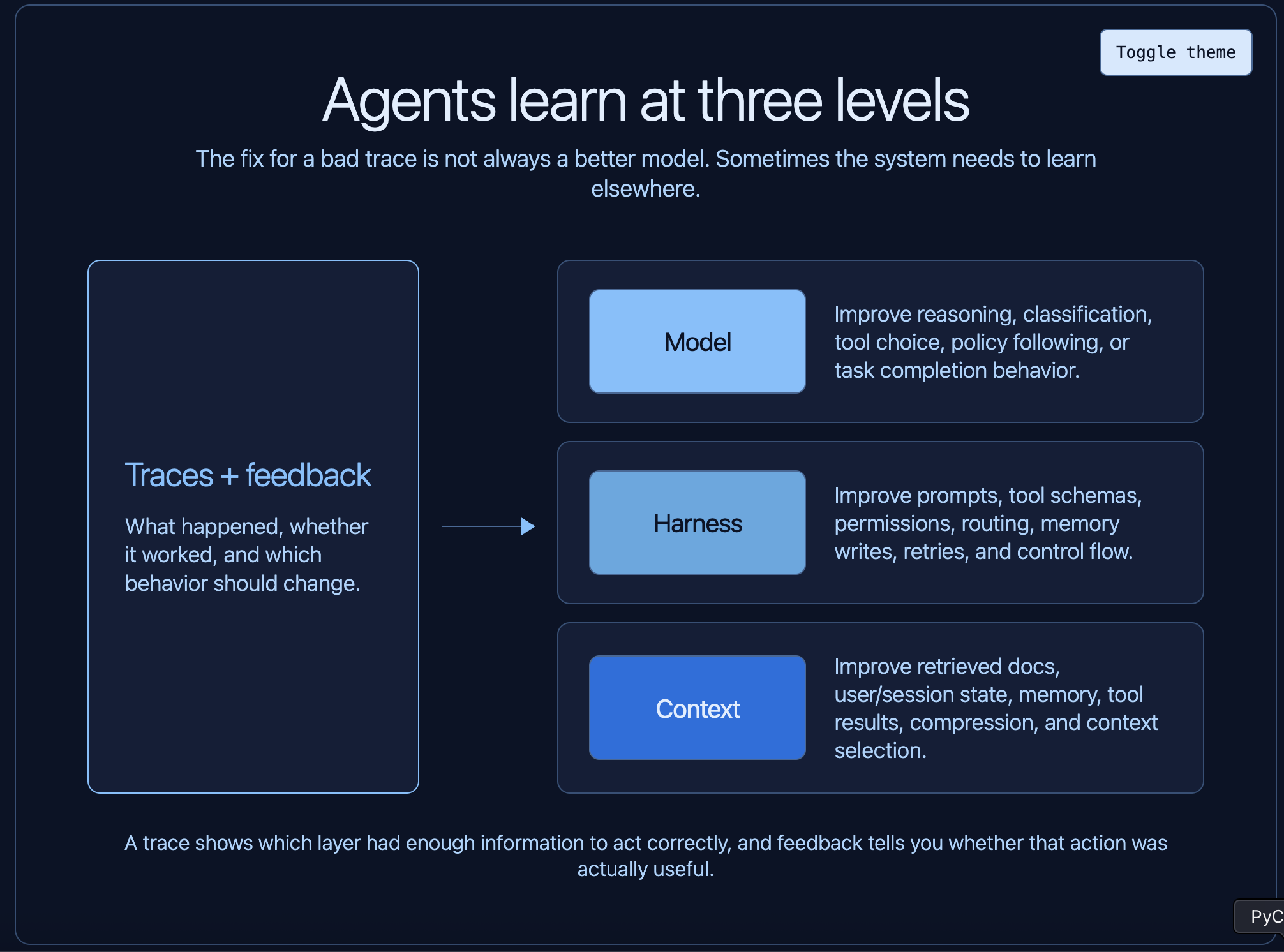
Learning can happen at the model level. You may discover examples where the model consistently misclassifies a request, chooses the wrong tool, or fails to follow a policy. Those traces can be used to update the model weights themselves, via SFT or RL.
Learning can happen at the harness level. The harness is everything around the model: prompts, tool schemas, permission checks, control flow, memory update logic, routing, retries, and guardrails. A trace might show that the agent had the right model capability but the wrong scaffolding. Maybe the tool description was ambiguous. Maybe the agent needed a read-before-write constraint. Maybe the system prompt made the wrong tradeoff.
Learning can also happen at the context level. Agents are extremely sensitive to the information they are given: retrieved docs, memory, user preferences, tool results, prior turns, environment state. A trace can show that the model made a reasonable decision given bad or missing context. In that case, the learning loop should improve what context is retrieved, stored, compressed, or discarded. This is commonly called memory.
The important point is that all of these learning loops are powered by traces. If you do not know what the agent saw, what it did, and what happened next, you cannot reliably know what to improve.
This is why agent observability powers agent evaluation. The trace is where agent behavior becomes visible.
Learning can be automated or hand-driven
Some learning is hand-driven. A developer looks at a trace, notices that the agent called the wrong tool, and updates the prompt or tool schema. A PM reviews a set of failed conversations and realizes the product needs a new workflow. An annotator labels traces so the team can build a better eval dataset.
This is still learning. It just has a human in the loop.
Other learning is automated. A system can sample production traces, run online evaluations, detect known failure patterns, add examples to a dataset, or trigger review queues when something looks wrong. The agent does not need to improve itself automatically for the learning loop to be automated. The automation may simply identify which traces deserve attention and turn them into structured feedback.
Either way, the process is powered by traces.
For one agent, with low volume, manual review may be enough. For many agents, or for high-volume production traffic, this becomes an infrastructure problem. You need to capture the traces, filter them, score them, route them, and preserve the ones that matter.
Traces are necessary, but not sufficient
A trace tells you what happened. It does not, by itself, tell you whether what happened was good.
That distinction matters. An agent can complete a task in 40 steps, but maybe the same task should have taken 6. It can produce a confident final answer, but maybe the user rejected it. It can avoid throwing an error, but still fail the user’s intent. It can call the right tool, but with subtly wrong arguments.
To learn from traces, you need feedback attached to them.
Feedback is what turns observability from a passive record into a training signal, debugging signal, product signal, or evaluation signal. Without feedback, you have a large pile of trajectories. With feedback, you can start asking useful questions:
- Which traces represent success?
- Which traces represent failure?
- Which failures are caused by the model, the harness, or the context?
- Which failures are worth turning into evals?
- Which behaviors are improving over time?
This is the core requirement: store feedback with your agent observability data.
Feedback can come from many places
Feedback does not have to mean a human manually grading every trace. In practice, useful feedback comes in several forms.

The most obvious is direct user feedback: thumbs up, thumbs down, a star rating, or a written correction. This signal is easy to understand, but it is usually sparse. Most users do not leave explicit feedback.
Then there is indirect user feedback. For a coding agent, this might be lines of code accepted, diffs reverted, tests passed after edits, or whether the user kept the generated change. For a support agent, it might be whether the user reopened the ticket. For a research agent, it might be whether the user copied the answer or asked the same question again. These signals are noisier than explicit ratings, but often much more plentiful.
You can also generate feedback with an LLM-as-judge. A judge can score whether an answer was helpful, whether an agent followed policy, or whether a trajectory looks suspicious. This is useful because it can run at scale, especially as an online evaluator over production traces. It is not perfect, and it should be calibrated, but it gives teams a way to create structured feedback where human review would be too slow.
Finally, feedback can be deterministic. Rules and regexes are underrated. If you know a failure pattern, encode it. If the agent should never call a destructive command without approval, check for it. If a response should contain a citation, validate it. If a coding agent shows signs of user frustration, detect it.
The Claude Code leak made this concrete. Multiple reports found that Claude Code used a regex in userPromptKeywords.ts to detect frustration words and phrases in user prompts. PCWorld reported that the regex looked for terms like “wtf,” “horrible,” “awful,” and “this sucks.” Slashdot’s summary includes the same pattern, and Blake Crosley’s analysis describes this as regex-based frustration detection rather than LLM inference.
From an engineering standpoint, the pattern is instructive. Not every feedback signal needs a model call. If a cheap rule captures a useful signal, use the cheap rule—and be clear about how that signal is stored and used.
What your observability platform needs
If observability is going to power learning, the platform needs three things.

First, it needs to store traces. This is the base layer. You need the full trajectory of what the agent did: model calls, tool calls, inputs, outputs, metadata, timing, errors, and intermediate state. Ideally, you can ingest traces from whatever stack you are using, not only one framework. LangSmith supports tracing from 30+ different frameworks, and can also ingest traces from OpenTelemetry-compatible applications through OpenTelemetry tracing.
Second, it needs to store feedback. Feedback should not live in a separate spreadsheet or analytics system disconnected from the trace. It should attach directly to the run, trace, or thread it evaluates. That lets you filter by feedback, compare good and bad trajectories, build datasets from real failures, and track whether changes improve the behaviors that matter. LangSmith supports capturing feedback and associating it with traces.
Third, it needs to generate feedback. Some feedback will come from users, but a lot of useful feedback should be produced by the system itself. That includes rules, evaluators, sampling, annotation queues, alerts, and backfills over historical traces. LangSmith supports automation rules and online evaluations, including LLM-as-judge evaluators that run on production traces.
This is the product shape that agent teams need: store traces, store feedback, generate feedback.
The learning loop depends on traces plus feedback
The point of observability is not just to look at traces. The point is to learn from them.
Traces tell you what happened. Feedback tells you what it meant. Together, they let you improve the model, the harness, and the context. They support hand-driven debugging and automated evaluation. They turn production behavior into datasets, rules, alerts, and regression tests.
Agent observability without feedback is incomplete. You can inspect behavior, but you cannot systematically learn from it.
To get the most out of agent observability, store feedback with your traces. That is what turns agent traces from logs into a learning system.