LangSmith vs. Langfuse

Key Takeaways
- LangSmith covers the full agent engineering lifecycle; Langfuse covers part of it. Langfuse handles tracing and prompt management, useful for early-stage LLM apps. LangSmith adds production evals automation rules, production alerting, and managed deployment for long-running agents.
- Several capabilities teams rely on at production scale are either missing or on the roadmap in Langfuse. LangSmith ships all of these, mentioned above, today—and adds a 30+ evaluator template library that covers trajectory evals, safety checks, and multimodal outputs that Langfuse doesn't address.
- Switching from Langfuse to LangSmith typically takes one to two weeks. LangSmith supports OpenTelemetry ingestion, so existing instrumentation carries over without modification. Most teams have their first traces running in LangSmith within a day. Dataset migration is a direct export/import, and LangSmith's Plus and Enterprise tiers include support throughout the process.
Langfuse traces your LLM calls. LangSmith traces and evaluates your AI agents, covering the complete agent engineering lifecycle: tracing, production evals, and managed deployment. This creates a data flywheel where production traces feed directly into datasets and evals, driving continuous improvement of your agents by enabling:
- End-to-end observability with automated production insights
- Offline and online evaluators
- Managed deployment for long-running agents
.png)
Get a demo of LangSmith's agent engineering platform
What sets LangSmith apart from Langfuse?
Langfuse fits teams that need tracing and prompt management for early-stage LLM applications. As your AI agents grow more complex, gaps emerge in evaluation depth and deployment infrastructure.
LangSmith gives you full lifecycle coverage from day one. LangSmith is framework agnostic: it requires neither the LangChain or LangGraph framework but works alongside both.
Where Langfuse reaches its limits
Langfuse works well for tracing and prompt management in early development. However, as your AI agents grow and reach production scale, certain limitations can slow down agent engineering.
Online deterministic evals are not yet available.
Langfuse's documentation confirms deterministic checks for online evaluation are "on the roadmap" but not in GA. However, LangSmith can run both LLM-as-judge and rule-based evals on live production traffic today.
No automation rules for the iteration flywheel
Without automation rules, routing traces to annotation queues or datasets requires manual action and means data doesn’t get reviewed. LangSmith's Automation Rules let you define logic once and let the system act on it continuously. You can route low-quality runs to human review, promote high-confidence runs directly to datasets, and trigger webhooks for downstream alerts or notifications.
No routing or assignment logic in annotation queues.
Langfuse's annotation queues documentation describes creating queues and processing tasks. It does not mention routing rules or priority-based distribution. As review volume grows, manual queue management can become a bottleneck.
No production alerting
Langfuse has no alerting functionality. LangSmith lets you configure custom alerts on run count, latency, and feedback scores—with webhook delivery and a PagerDuty integration. For teams monitoring live agents, the inability to get notified when error rates spike or latency degrades means catching issues reactively rather than proactively.
Fixed permission roles with no customization
Langfuse offers five pre-defined roles—Owner, Admin, Member, Viewer, and None—with no ability to adjust permissions within each role. LangSmith supports granular, custom permissions. For enterprise teams with multiple stakeholders working on a project (engineers, PMs, domain reviewers, compliance), fitting everyone into fixed roles creates friction and security gaps.
Self-hosting at low-scale lacks high availability.
Langfuse's documentation states that their deployment "lacks high-availability, scaling capabilities, and backup functionality." Production-grade self-hosting requires a more complex stack.
Evaluator template library is limited in scope
Langfuse ships 8 built-in templates covering basic response quality—hallucination, helpfulness, relevance, and a few others. LangSmith has 30+, including categories Langfuse doesn't cover at all: trajectory evaluation (did the agent take the right steps?), safety checks like prompt injection detection and PII identification, and multimodal evals for voice and image outputs. Pre-built templates also can't be modified directly in the Langfuse UI, so customization means starting from scratch.
UI can confuse non-technical reviewers doing annotation.
GitHub Discussions from Langfuse users describe overlapping ways to view and score traces. Domain experts have mentioned they find the interface harder to navigate during evals. Langfuse also lacks a trace compare view—there's no way to view multiple traces side by side. Their UI does not auto-refresh when new traces come in, requiring manual intervention to see live data. Experiment comparisons use line graphs rather than bar charts, which makes reading results across multiple runs difficult to parse.
Why choose LangSmith over Langfuse?
LangSmith addresses each of these limitations with purpose-built capabilities that accelerate workflows. The platform creates a closed feedback loop connecting every stage of the agent engineering lifecycle:
- Production traces automatically feed into datasets through one-click conversion, turning real-world failures into regression tests.
- The Insights Agent analyzes production traces to discover usage patterns and failure modes that manual review would miss.
- Insights translate directly into evaluation criteria, enabling systematic quality improvements rather than ad-hoc fixes.
- Evaluation results inform prompt refinements and build better datasets, creating a continuous improvement cycle.
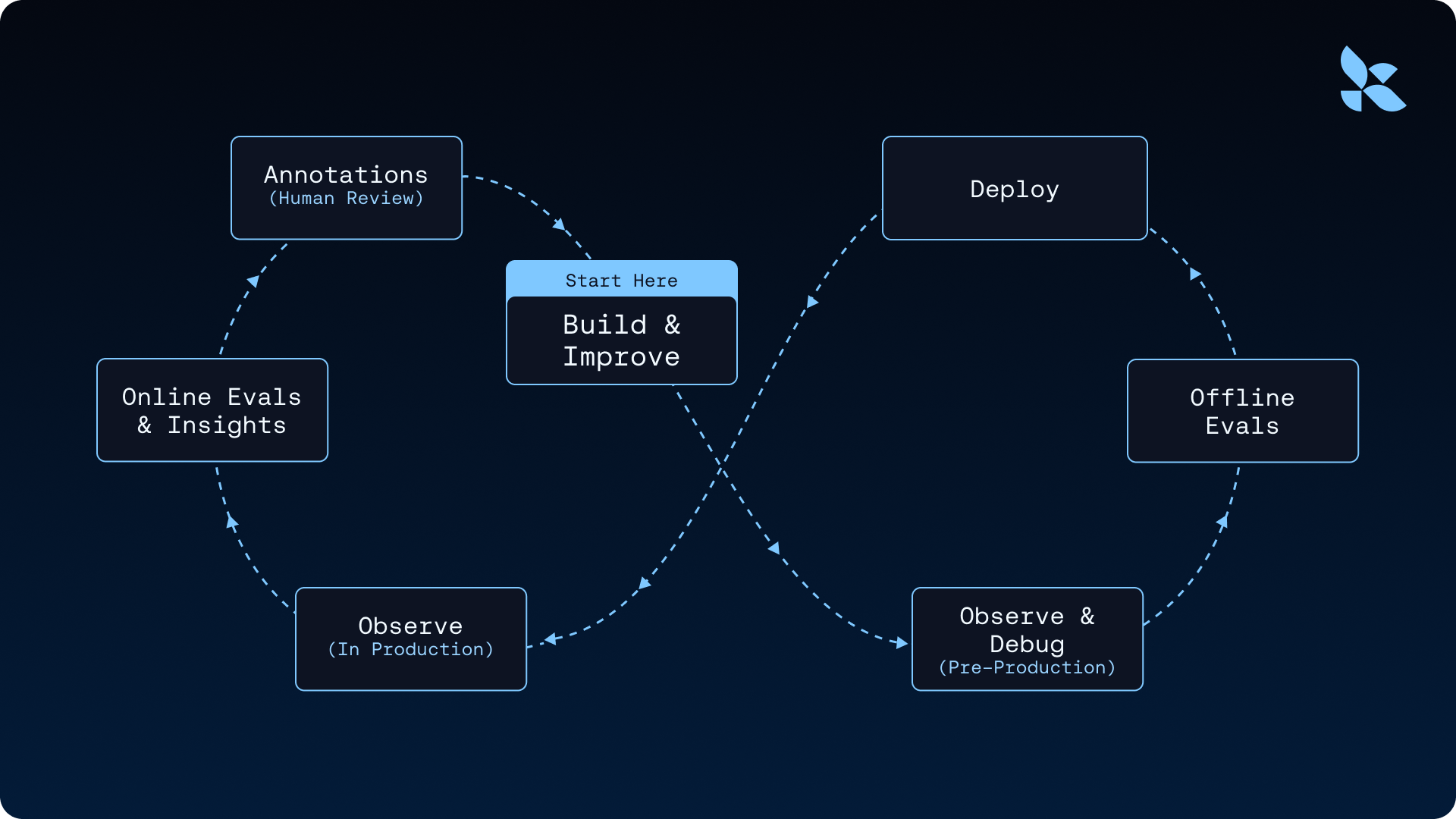
This integrated approach moves teams from "vibes-based" development to metric-driven engineering, where production data drives systematic agent improvements rather than guesswork.
Production evals that go beyond tracing
Langfuse's evaluation roadmap has significant gaps. Online deterministic checks are still in development, which LangSmith provides out-of-the-box, giving you production-ready evaluation tools from day one.
LangSmith runs offline evals on curated datasets, giving you regression testing before every deploy. You can run experiments and compare results across different prompt versions or model configurations to ensure quality improvements are real.
Online evals monitor your production traffic in real-time. As your agents respond to live requests, LLM-as-a-judge evaluators automatically score each response against your quality rubrics. Rule-based evaluators catch format violations and hallucination patterns, giving you feedback without manual review.
Human review workflows that scale with your team
LangSmith's annotation queues fill the gaps in Langfuse's routing and consensus capabilities. PMs and domain experts get structured workflows instead of manual queue management.
Your team defines routing rules that direct queue items where they need to go. High-risk outputs get reviewed first through priority scoring. Load balancing spreads work evenly across all annotators.
Production alerting that catches issues before users do
LangSmith's alerting lets you define thresholds on latency, error rates, run count, and feedback scores, then route notifications to your existing incident management stack—including PagerDuty and custom webhooks. When a production agent starts degrading, your team knows immediately rather than discovering it through user complaints. Langfuse has no equivalent capability.
Enterprise RBAC for teams with multiple stakeholders
LangSmith's role-based access control lets you define granular, custom permissions per role—so engineers, reviewers, PMs, and compliance teams each get exactly the access they need, nothing more. Langfuse's five fixed roles can't accommodate the access patterns most enterprise teams actually have. When a domain expert needs to annotate runs but shouldn't modify datasets, or a compliance reviewer needs read-only trace access, fixed roles become a workaround problem rather than a solution.
Automated insights that discover patterns across traces
Langfuse's Score Analytics limits analysis to two-score comparisons. At production scale, teams need pattern discovery to happen automatically. LangSmith's Insights Agent automatically analyzes your trace data to surface patterns you wouldn't find through manual review. The system identifies failure clusters across millions of traces and detects tool-call anomalies without requiring human intervention.
LangSmith feeds those insights directly into new evaluations. When you discover an unknown failure mode, you can translate it into an evaluation criterion and monitor for it in future production runs. This creates a continuous improvement cycle where production data strengthens your quality checks.
Managed deployment for long-running AI agents
Langfuse does not offer infrastructure for running your AI agents in production. LangSmith does.
LangSmith Deployment provides managed runtime for stateful agents. The platform handles task queues and persistence automatically. It includes built-in human-in-the-loop pauses and horizontal scaling to handle bursty workloads.
One-click GitHub deploys remove the infrastructure overhead.
Switching from Langfuse to LangSmith
LangSmith preserves your existing instrumentation because the platform is framework agnostic and supports OpenTelemetry ingestion. Your current traces transfer without modification. Simply add the traceable wrapper to any Python or JS/TS application to start capturing traces immediately, regardless of which framework you use.
Your evaluation datasets migrate just as easily. Export datasets from Langfuse and import them into LangSmith to maintain your existing test coverage. Most teams capture their first traces in LangSmith within a day, while full migration typically takes one to two weeks. This timeline includes transferring datasets and configuring evaluations to match your quality criteria.
LangSmith Plus tier includes support throughout the migration process, and Enterprise tier LangSmith customers work with a dedicated support engineer during the migration process and beyond.
.png)
Use cases where LangSmith excels
Production AI agents in regulated industries
LangSmith's annotation queues with filter-based automations enable structured human review for high-risk outputs. Domain experts and product managers can evaluate each response against your quality criteria. Online evaluations run continuously on production traffic, flagging policy violations. Full trace lineage provides the audit trail that compliance teams need to demonstrate quality controls are working as intended.
Multi-model AI agent architectures
LangSmith provides visibility across multi-model architecture. Every step in your agent workflow appears in the trace, from the initial model call through tool executions and handoffs between models. When you swap models to optimize for cost or accuracy, built-in evaluations quantify the quality tradeoff.
Scaling from prototype to production
LangSmith helps teams scale from prototype to production by turning production data into systematic improvements. AppFolio used LangSmith's tracing and evaluation tools to improve their text-to-data feature from 40% to 80% accuracy while expanding the number of actions and data models users can query. The platform helped them identify incorrect examples in their dynamic few-shot prompting system, iterate rapidly in the playground without code changes, and run evaluations to prevent regressions.
Move from vibes-based development to metric-driven agent engineering
LangSmith gives you the observability, evaluators, and deployment infrastructure to ship agents you can trust in production.
Get a demo of LangSmith's agent engineering platform
Frequently asked questions
Is Langfuse a product of LangChain?
No. Although frequently confused, Langfuse is a product by ClickHouse, and not part of the LangChain product suite. LangChain has created LangSmith, `deepagents`, LangGraph, and `langchain`.
How long does it take to switch from Langfuse to LangSmith?
Most teams capture their first traces in LangSmith within a day. Full migration, including evals and dataset porting, takes one to two weeks for most teams.
Will I lose data when migrating from Langfuse?
No. You export datasets from Langfuse and import them into LangSmith directly. Trace history stays in your Langfuse instance until you choose to decommission it.
Is LangSmith only for teams using the LangChain framework?
No. LangSmith is framework agnostic. While it works seamlessly with the LangChain, LangGraph, and Deep Agents frameworks, it also supports OpenAI SDK and custom stacks. Any application instrumented with the traceable wrapper works with LangSmith.
What happened with Langfuse and Clickhouse?
Clickhouse acquired Langfuse. The long-term impact on Langfuse's product roadmap and investment priorities is uncertain. It’s important to evaluate current feature coverage and roadmap commitments when making your decision.
Does LangSmith support self-hosting?
Self-hosting is available on LangSmith's Enterprise tier, which also includes dedicated support and BAA signing for regulated industries.
Does LangSmith have production alerting?
Yes. LangSmith lets you configure custom alerts on run count, latency, and feedback scores, with delivery to PagerDuty or any webhook endpoint. Langfuse does not currently offer alerting.
How does LangSmith handle permissions for large teams?
LangSmith supports granular, custom RBAC. You can define specific permissions per role—so engineers, reviewers, PMs, and compliance teams each get the right level of access. Langfuse offers five fixed, pre-defined roles that cannot be customized.
Get started with LangSmith today or speak with our team to build the evaluation workflow your AI agents deserve.