LLM Evals: The Feedback Loop Behind Reliable AI Agents
March 10, 2026
An LLM eval is a structured test that scores what a model or agent produces against a defined expectation, whether that's a reference answer, a policy rule, a functional check, or a quality rubric. But a score by itself is just a number, and plenty of eval programs stall there. A score is only useful when it changes what ships, by becoming a dataset example, an online monitor, or a context fix.
Shipping an AI agent is rarely a single launch. Teams build a version, test it before release, deploy it, then monitor it in production and use what they learn to build the next version. That repeating loop has a name: the Agent Development Lifecycle (ADLC). Evals do the heavy lifting in two stages of the lifecycle. During testing, before deployment, evals compare versions so you can see whether a change made the agent better or worse. During monitoring, after deployment, evals score real production traces and feed failures back into the next version, so a trace that exposes a problem becomes a testable example with inputs and pass/fail criteria, not just a screenshot in a ticket.
How LLM evals differ from benchmarks
Benchmarks and evals both produce scores, but they answer different questions.
A public benchmark like MMLU or SWE-bench measures a model's raw capability against a fixed, shared test set. That is exactly what you want when you are choosing a base model. It tells you almost nothing about whether your agent does its job, because your agent runs a specific task, on your data, against your policies, wrapped in the prompts, tools, and retrieval layers that never show up in the benchmark.
An eval scores that whole system on the behavior you actually care about: did it follow the policy, cite the right document, recover when a tool call failed?
The two are also used at different times. You usually look at benchmark results once, when you're choosing a base model. You run evals continuously, as you change the agent around it. Both of those distinctions point to the same underlying problem: agents are unusually hard to evaluate.
What makes agents hard to evaluate
Most traditional software is easy to test: you give it a specific input, expect the same output every time, and “correct” means matching the one answer you were looking for. AI agents break both of those rules, which is why testing them takes its own approach.
- The same question can produce different answers. Ask an agent the same thing twice and you might get two replies that are both fine. Comparing its output word-for-word against one expected answer would flag many of those good replies as wrong, so an exact-match check does not work here.
- There is often no single correct answer. A support reply, a summary, or a research plan can each be done well in several different ways. Since many different responses are all acceptable, scoring the agent by how closely it matches one reference answer would penalize replies that are correct but worded differently, so these outputs have to be judged against a description of what good looks like instead.
- Agents fail in new ways. They can state false information as fact, be manipulated into ignoring their own instructions, produce harmful content or responses that violate the policies they were given, or call their tools in the wrong order. None of these failures show up as crashes or error messages. Code can run cleanly and pass functional tests, yet still return an answer that's wrong, unsafe, or against the rules.
Because the answers vary and the failures are about behavior rather than broken code, evals usually grade a response against a written checklist of what “good” looks like, or have a second AI model score it (an approach called LLM-as-a-judge), instead of checking for one exact match. And since a single number rarely captures all of this, one score is rarely enough. Catching these failures in a system that keeps changing is where the agent development lifecycle comes in.
Where LLM evals fit in the agent development lifecycle
Evals do their clearest work at two points in the lifecycle: before you ship (to catch regressions) and after you ship (to catch drift and recurring failures).
- Test, before you deploy: is the new version ready to release? You run it against a saved set of example inputs with known-good answers and compare its scores to the previous version's. If a change made the agent worse at something it used to get right (a regression), you hold the release until it's fixed.
- Monitor, after you deploy: is the live agent still behaving well with real users? You score real production traces, but unlike testing you rarely have a known-correct answer to compare against (a reference answer), so you grade against signals like policy misses and recurring failure modes instead.
Test and monitor need different data
Testing and monitoring use different setups because the data comes from different places. When you test before launch, you write the inputs yourself. Once the agent is live, users supply the inputs, and they are unpredictable. That difference is why teams split their eval workflow: one setup for curated datasets while testing, and another for messy, reference-free production traces while monitoring.
Offline evals run against datasets where you control the examples. Online evals run against production traces where users supply the inputs and the system doesn't have a reference output.
Once the system is deployed as a production agent, thread-level evaluation catches failures a single run can miss. One message can look acceptable while the full conversation fails the user's goal, loses context, or takes a wasteful trajectory, so evaluating the whole thread lets the monitor stage score the outcome rather than an isolated reply.
LangSmith Evaluation supports both offline and online evals because each stage has a different job. Because LangSmith is framework agnostic, this approach works whether you build on LangChain, LangGraph, Deep Agents, another framework, or custom code.
Name failures before scoring them
Ask two reviewers to score an answer for "helpfulness" and you'll often get two different numbers on the same trace. Scores like helpfulness, hallucination, and coherence feel actionable until that disagreement surfaces, and then the team realizes the metric never had a shared definition.
Trace review should end with three outputs: a named failure mode, labeled examples, and the evaluator you will use.
Base the label on evidence from messages, tool calls, retrieved context, model inputs, outputs, and user feedback. That evidence is what turns a vague score into a failure described in real-world terms the team can act on.
Inspecting that evidence usually reshapes the evaluation criteria too. The failure modes you name before reading real traces are educated guesses, so keep the rubric editable while reviewers work and let the first label pass correct it. That early drift is the team learning what the rubric should have said, and it's also when vague metric names start turning into concrete descriptions of what went wrong.
Those descriptions are more useful than broad metric names because the team can act on them:
- Rescheduled a tour when no slot existed
- Skipped the required policy disclaimer
- Cited a stale document
- Called the refund tool before verifying eligibility
Match each failure mode to the evaluator that can actually observe it.
LLM-as-a-judge evals need the same discipline as a classifier. A narrow pass/fail question is easier to calibrate than a broad quality score. Start from labeled traces because they anchor your metrics in real failures with inspectable evidence, which makes it easier to choose the right evaluator and turn production issues into regression coverage by adding them to offline datasets and wiring up online evaluators to catch recurrence.
Keep train, development, and test sets separate, especially when you track precision, recall, false positives, and false negatives for rare failures. Calibrate the judge against those sets and its scores become reliable enough to gate a release, instead of just populating a dashboard.
Turn production failures into regression coverage
When you fix a failure manually, the fix and the eval that should catch it next time get created separately, often at different times, by different people, in different tools. LangSmith Engine keeps trace review, fix writing, regression tests, and monitoring setup attached to a single issue, so the diagnosis, proposed fix, and coverage recommendation stay together.
Inside a single issue, Engine runs that loop as an ordered sequence:
- Analyzes production traces for patterns in unmet expectations or failures
- Clusters the related traces into an issue with severity and evidence
- Diagnoses the root cause against the relevant prompt or code
- Proposes a fix as a prompt change, code change, or PR for review
- Suggests an online evaluator to catch recurrence in production
- Recommends examples for offline eval datasets so future experiments catch the regression
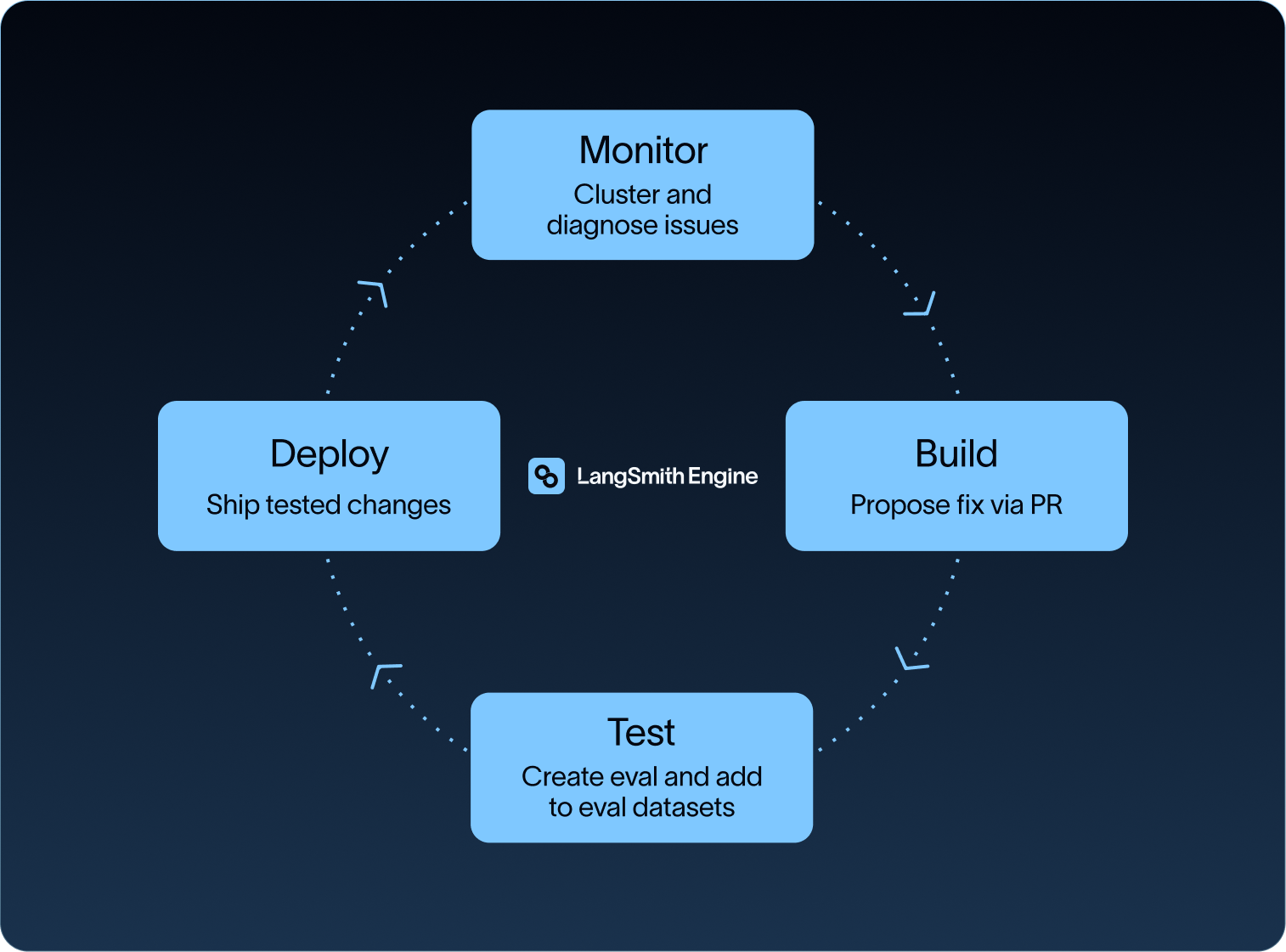
After a production failure, Engine keeps the issue tied to the proposed fix and the eval coverage that should follow. Keeping them together makes it harder to ship the fix without also adding the dataset example, online evaluator, or monitor that should catch the failure next time. Engine stops at the review step. It proposes the issue, the fix, and the coverage. From there, the team reviews the diagnosis, refines the change, and decides what ships.
Many eval failures are really context failures
Plenty of eval failures don't trace back to the model at all. They come from stale instructions, a missing policy example, an unclear tool description, or a skill that no longer matches how the team works. Context Hub gives those context fixes a versioned home.
Context Hub manages the context files agents rely on (instructions, skills, examples, and policies) with version control and environment tags, where a context can be a single skill or a full agent that a team promotes across environments. That versioning makes eval fixes reusable: if an online eval flags a recurring policy miss, the fix can be a new example or instruction.
If offline evals show that a new prompt passes only with a certain context file, that context version should move with the release. Context Hub gives those changes file history and environment promotion instead of leaving them in an untracked document.
Context Hub also widens who can help. Product managers and subject matter experts often know the policy, escalation rule, or example that makes the agent better.
Versioned context lets a PM or domain expert submit the corrected policy or example as a tracked change that engineers review and promote like any other release artifact, so the people who know the rule can fix it without touching the deployment.
Trace data needs a database built for it
Monitoring an agent in production means digging through its traces, and trace data punishes a general-purpose database. A single trace isn't one tidy record: it arrives in pieces and forms a deeply nested tree as the agent calls tools, retrieves context, runs code, and resumes across sessions.
Now multiply that by millions of traces, then filter them by metadata, feedback score, latency, errors, tags, and tool calls to find the pattern you're chasing. When those queries lag, investigations stall and the backlog grows faster than the team can clear it.
SmithDB is LangSmith's data layer for agent observability and evaluation workloads, designed for traces that arrive in pieces and nest deeply. It reports P50 latencies of 92ms for trace tree loads, 71ms for single run loads, 82ms for run filtering, and 400ms for full-text search, making core LangSmith experiences up to 15x faster.
When monitoring, the team needs to find the trace, filter the pattern, inspect the thread, and decide whether the online evaluator is catching the right signal. The clustering and root-cause analysis in an autonomous loop depend on the same nested details, like agent trajectory, tool call latency, and feedback quality scores. With those signals in view, monitoring stays a live investigation instead of an overnight query job.
Sandboxes make code evals safe
When an agent writes code, runs shell commands, installs packages, transforms files, or edits a filesystem, scoring the final text tells you almost nothing about whether it worked. The eval has to watch the execution itself, which means running that code in an isolated environment rather than against production. That gives the eval behavioral evidence: exit status, file changes, and command behavior, instead of just the final answer.
What teams should evaluate
Start with deterministic checks that confirm exit status, required files, test results, output format, and credential boundaries. From there, add LLM-as-a-judge evals for higher-level behavior such as whether the agent made a reasonable plan or resolved the user's task.
Use sandboxes before and after you ship
Sandboxes are useful at both stages where evals matter: testing before release and monitoring after deployment. Before you ship, they make your functional checks realistic, because the agent actually executes the task instead of being graded on a description of it. After you ship, traces from sandboxed runs show what happened inside the execution environment, so a real failure becomes a reusable dataset example instead of a vague report that the coding agent produced a bad result.
LangSmith Sandboxes capture that execution evidence directly, so a code-execution agent gets regression tests that rerun the task instead of re-reading the model's description of it.
Start with one trace
You don't need a finished eval suite to begin. Pick a trace that has negative user feedback, a low online-eval score, or a conversation that reached the wrong outcome, then run it through the whole agent development lifecycle loop (build, test, deploy, monitor).
- Name the failure mode in product language
- Decide whether the right evaluator is code/functional, LLM-as-a-judge, or human review
- Add the trace to an offline dataset with the expected behavior
- Create one online evaluator that watches for recurrence
- Version the context change in Context Hub if the fix changes instructions, policies, skills, or examples
- Use LangSmith Engine to keep finding related traces and proposed coverage
From there, let LangSmith Engine run the loop for you, surfacing the next failures and proposing their coverage automatically.