

Key Takeaways
DeltaChannel stores only the delta each step and writes periodic full snapshots every K steps, bounding resume latency while keeping storage costs flat as sessions grow longer.messages and files are delta-backed by default in Deep Agents v0.6, and the full LangGraph API surface (interrupts, time-travel, tooling) is unchanged.Deep Agents is built on the LangGraph runtime, which checkpoints agent progress at every step. That's what makes observability, human-in-the-loop, and failure recovery possible: you always know exactly where an agent is and can resume from any point.
As agents get more capable:
- They run longer, with message histories that grow across dozens or hundreds of steps
- They use more context, utilizing the filesystem for context management and offloading
For Deep Agents, message history and files live in agent state, and with a snapshot-every-step approach, checkpoint storage grows at O(N²). For a coding agent running 200 turns, current checkpointing methods serialize 5.3GB to the checkpointer. Delta channels bring it to 129 MB, over a 40x reduction, with practically no performance drop in state rehydration.
Delta channels are how we're evolving the runtime to keep up. DeltaChannel is a new primitive in langgraph 1.2 that changes how accumulating state fields are checkpointed. Rather than serializing a full snapshot at every step, each step stores only the diff. Full snapshots are written periodically to bound recovery cost. For Deep Agents, that means delta-based storage for messages and files. You still get a complete history of agent progress, just at a fraction of the cost.
Checkpoint storage in LangGraph grows at O(N²) for agents with long message histories. For a coding agent running 200 turns, that's 5.3 GB. Delta channels bring it to 129 MB — a 41× reduction, for free.
The problem: O(N²) checkpoint storage
The default LangGraph checkpointing model writes a full snapshot of agent state at every step. For small, short-lived agents this is fine. But messages and files are append-only accumulators — they only ever grow.
Under full-snapshot checkpointing, checkpoint N contains everything from steps 1 through N:
%201.png)
The growth compounds across the checkpoint layer: each step serializes more data than the last, writes a larger blob to the checkpointer, and consumes more memory to hold it. You're paying in serialization time, write amplification, and redundant storage.
The solution: Delta Channels
Channels are the LangGraph primitive used to represent a “field” in graph state. Different channel types control how data is passed through checkpoints.
DeltaChannel is a new LangGraph channel type (in beta as of 1.2) that changes the checkpoint representation for accumulating fields.
On a normal step, a DeltaChannel writes only the new updates added that step, a tiny delta.
Full snapshots are written every snapshot_frequency=K steps (default: 50 for deepagents). This bounds the cost of reconstructing state on resume: rather than replaying every delta write since the beginning of the session, the runtime only needs to walk back to the nearest snapshot — at most K steps. Without periodic snapshots, a very long session would mean very slow resumes.
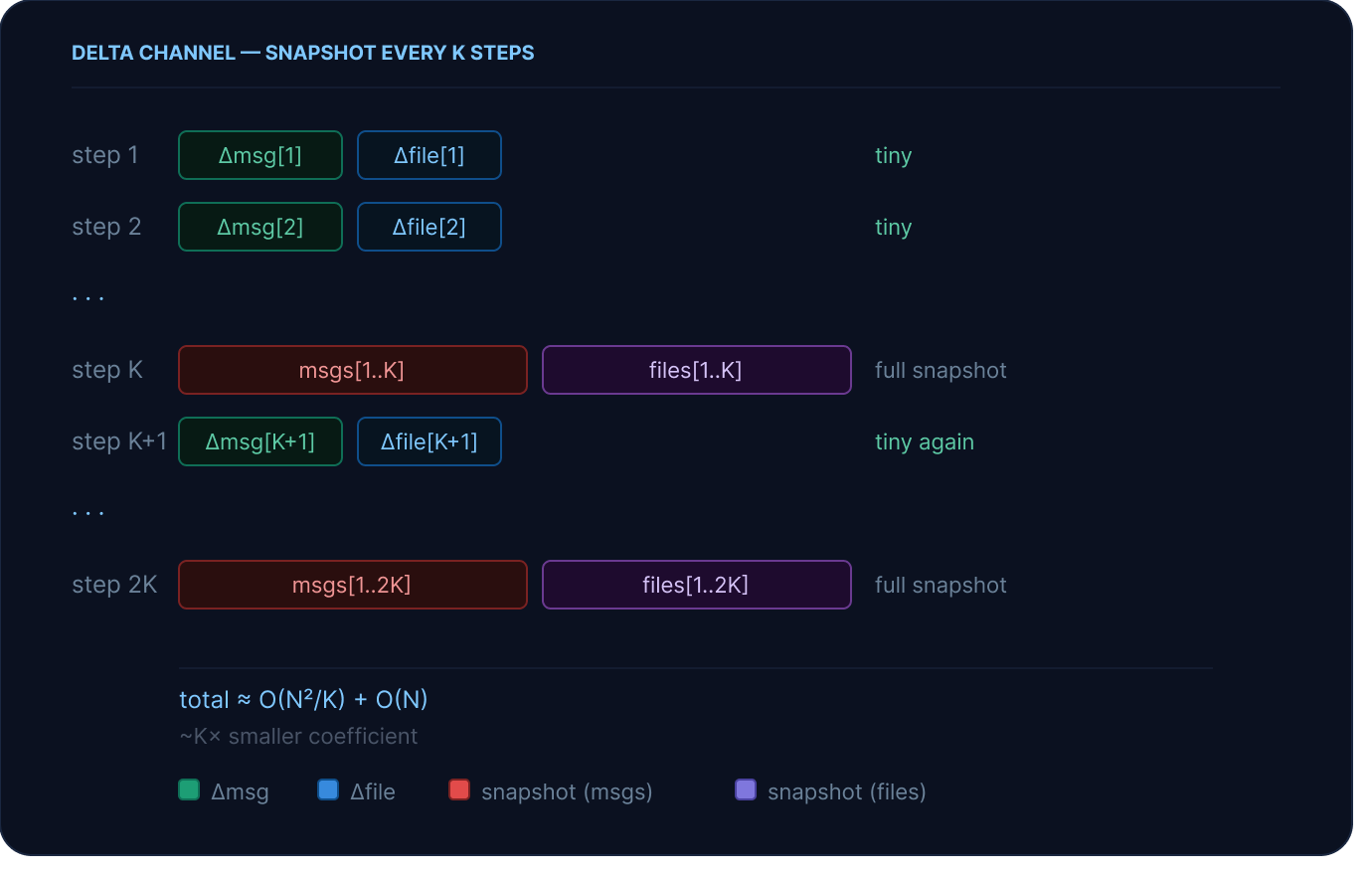
The underlying growth is still quadratic (because snapshots happen every K steps), but the coefficient is ~1/K of the baseline. The O(N) delta term dominates at practical session lengths, and because reconstruction cost is bounded by K, resume latency stays flat. The storage win is effectively free.
Here’s a side by side comparison of the standard snapshotting approach vs the delta approach:
%20(1).svg)
Benchmark Results
DeltaChannel is a LangGraph primitive, but the workload that motivated it, and the one we're benchmarking here, is a Deep Agents coding session. Long message histories and filesystem-backed context offload are exactly the state shape where O(N²) checkpoint growth becomes a real operational problem.
We ran two workloads:
The periodic large search results exceeded FilesystemMiddleware's 20k-token eviction threshold and gets offloaded from messages to files.
Methodology
All benchmarks use fully mocked workloads — no real LLM calls, InMemorySaver, deterministic mock model, fully reproducible. Tables report total checkpointer storage: all bytes accumulated in the saver across the entire session. Token counts use the total_message_chars / 4 approximation that FilesystemMiddleware uses internally for its eviction threshold.
The setup looked like the following:
```py
checkpointer = InMemorySaver()
agent = create_deep_agent(
model=_MockModel(), # deterministic mock, no API calls
tools=[external_search],
checkpointer=checkpointer,
)
for i in range(turns):
agent.invoke({"messages": [HumanMessage(...)]}, config)
```Workload A: light coding and search
Storage grows slowly at first, then accelerates sharply as the full snapshot size compounds. At 500 turns the baseline has accumulated 4 GB; delta channels stay under 110 MB.
%20(1).svg)
The savings ratio grows from 6× at 10 turns to 41× at 500 — still climbing, but decelerating as it approaches the theoretical ~K× ceiling. That ceiling isn't fixed: snapshot_frequency is configurable, so you can trade resume latency for storage savings based on your workload. A higher K means fewer full writes per session and a higher storage reduction, at the cost of slightly more delta replay on resume.
.svg)
Workload B: multi file coding session
Heavier per-turn state means the O(N²) curve steepens faster. The baseline hits 5.3 GB at just 200 turns — a realistic afternoon of agent work.
%20(1).svg)
The savings ratio reaches 41× at 200 turns and is still climbing — both workloads converge toward the same ~K× asymptote, but the heavier workload gets there faster because larger per-turn writes amplify the quadratic coefficient more aggressively.
.svg)
The savings ratio is consistently higher for Workload B at each turn count because larger per-turn state amplifies the O(N²) coefficient faster. Both workloads converge toward the same asymptote (~snapshot_frequency×), but the heavier workload gets there sooner.
The API
In Deep Agents
Delta channels are on by default in deepagents v0.6 Both messages and files are delta-channel-backed. No configuration required.
In LangGraph
DeltaChannel is a first class primitive in LangGraph that you can use for any state field.
from typing_extensions import Annotated
from langgraph.channels.delta import DeltaChannel
def append(state: list[str], writes: list[list[str]]) -> list[str]:
return state + [item for batch in writes for item in batch]
class MyAgentState(TypedDict):
items: Annotated[list[str], DeltaChannel(reducer=append, snapshot_frequency=50)]Two parameters:
reducer— a pure function(state, list[writes]) -> new_statethat must be batching-invariant:reducer(reducer(s, xs), ys) == reducer(s, xs + ys). See the reducer contract below.snapshot_frequency— how often to write a full snapshot (default: 1000). Higher values mean fewer full writes per session but more delta replay on resume.deepagentsuses 50.
That's the entire API surface change. Existing tools, interrupt handling, and time-travel all continue to work.
The reducer contract: associativity across folds
DeltaChannel imposes a stricter requirement on the reducer than the old BinaryOperatorAggregate channel. This is the one thing to get right when defining your own delta-backed state.
The old contract
def reducer(existing: T, update: T) -> T: ...The new contract
# Batch fold — called with ALL accumulated writes at once
def reducer(state: T, writes: list[T]) -> T: ...
DeltaChannel passes all writes accumulated since the last load in a single call. The reconstructed result must be identical regardless of how those writes are batched:
reducer(reducer(state, [w1, w2]), [w3, w4]) == reducer(state, [w1, w2, w3, w4])This is called batching-invariance. If your reducer violates it, delta channel state will diverge from a full snapshot, silently, and only for sessions that span a snapshot boundary.
Migration from pre-delta threads
No data migration required. When DeltaChannel.from_checkpoint encounters a plain state value (not a _DeltaSnapshot), it uses it directly as the base state. Existing threads continue to work — the first new checkpoint after the upgrade begins writing deltas on top of that plain-value seed.
What’s next
Delta channels ship in deepagents v0.6 and langgraph v1.2. The upgrade path should be seamless.
The gains associated with delta channels compound as sessions get longer. Long-running agents with deep context are where the field is heading, and delta channels are how our runtime scales to meet their needs.





