

Key Takeaways
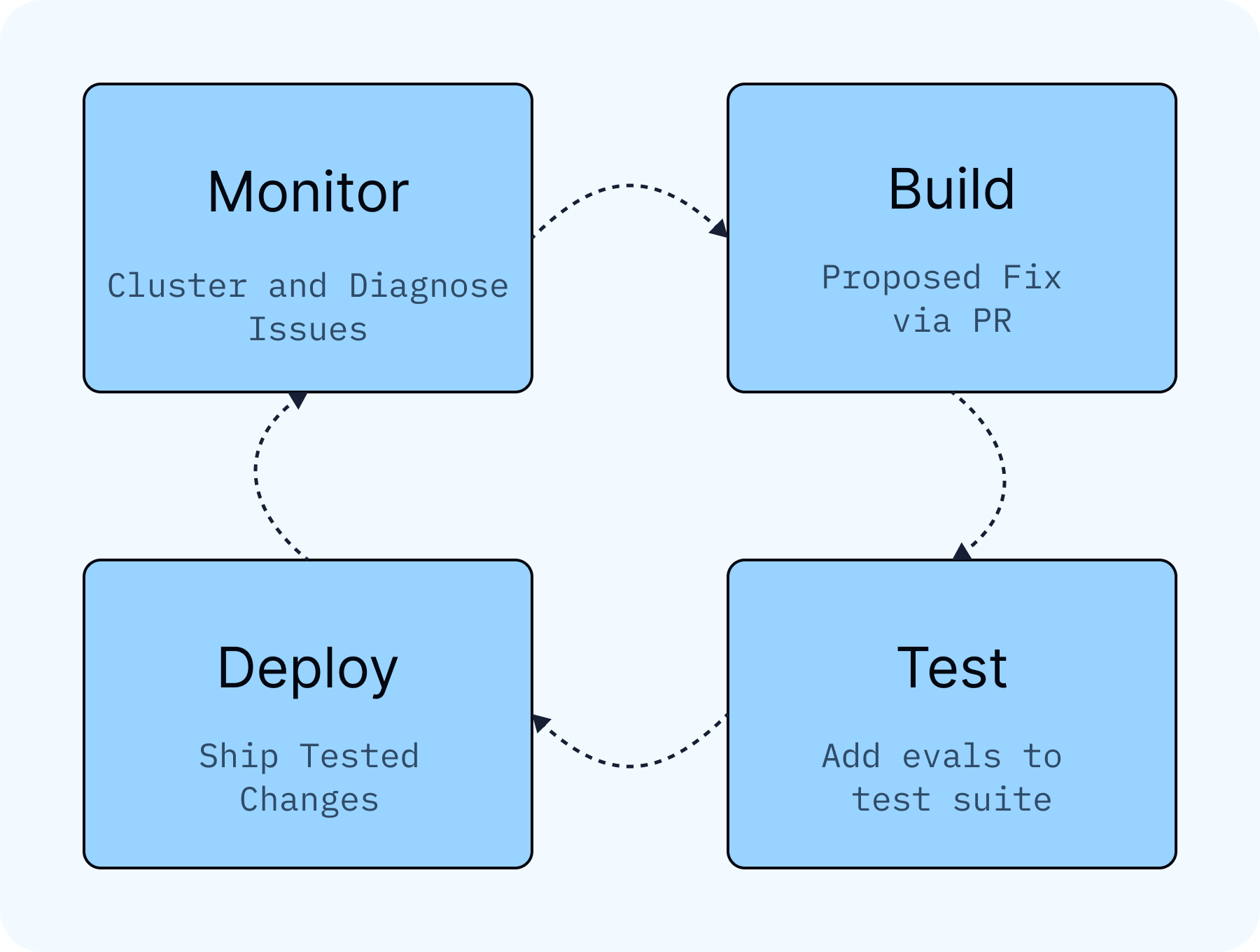
- The agent development lifecycle now moves faster. LangSmith Engine replaces the manual cycle of reading traces, spotting patterns, and writing fixes by doing it continuously — clustering production failures into named issues, diagnosing root causes against your code, and drafting PRs and evaluators for your review.
- Every resolved issue makes your eval suite stronger. When Engine surfaces a fix, it also proposes a custom online evaluator and pulls failing traces into your offline eval dataset — so the same failure can't silently recur after you ship.
- It's built on top of your existing LangSmith setup. Engine plugs into your current tracing projects, evaluator results, and repositories — no new infrastructure required. Connect a project, optionally connect your repo, and it starts surfacing issues from production automatically.
Today we're launching LangSmith Engine.
Until now, improving your agent has been a manual process of reading traces, looking for patterns, writing evals, and creating fixes. Now LangSmith Engine can run that cycle for you. It watches your production traces, clusters failures into named issues, diagnoses root causes against your code, and proposes fixes and eval coverage to keep regressions from coming back. You just review and merge improvements.
LangSmith Engine is available today in public beta.
Every agent team runs the same cycle
The typical agent development cycle looks like this:
- Trace your agent to understand what it's doing
- Identify patterns in failures or gaps in functionality
- Make changes to prompts, tools, logic, or structure
- Create ground truth datasets from production traces
- Run experiments to confirm improvements and check for regressions
- Ship and repeat
LangSmith already gives you trace views, fast dataset creation, and experimentation to support each step. But we kept hearing the same friction points from customers:
- Knowing what to fix is hard because individual trace review doesn't reveal patterns.
- Seeing how often an error recurs across traces is difficult at scale.
- Creating ground truth examples for offline evals from production data is tedious and easy to skip.
- Once a fix ships, there's often no targeted evaluator in place to catch the same problem if it comes back.
Engine works across the entire cycle. Teams see clustered failures in a prioritized list, get fixes drafted automatically, and have offline eval examples proposed for their test suite.
What an issue looks like in practice
Say your agent is a customer support bot. Engine detects a cluster of traces where users ask about canceling their subscription. Your agent responds, but online evals are scoring the responses as failures and user feedback is negative. Latency is normal, so no systems alert fired.
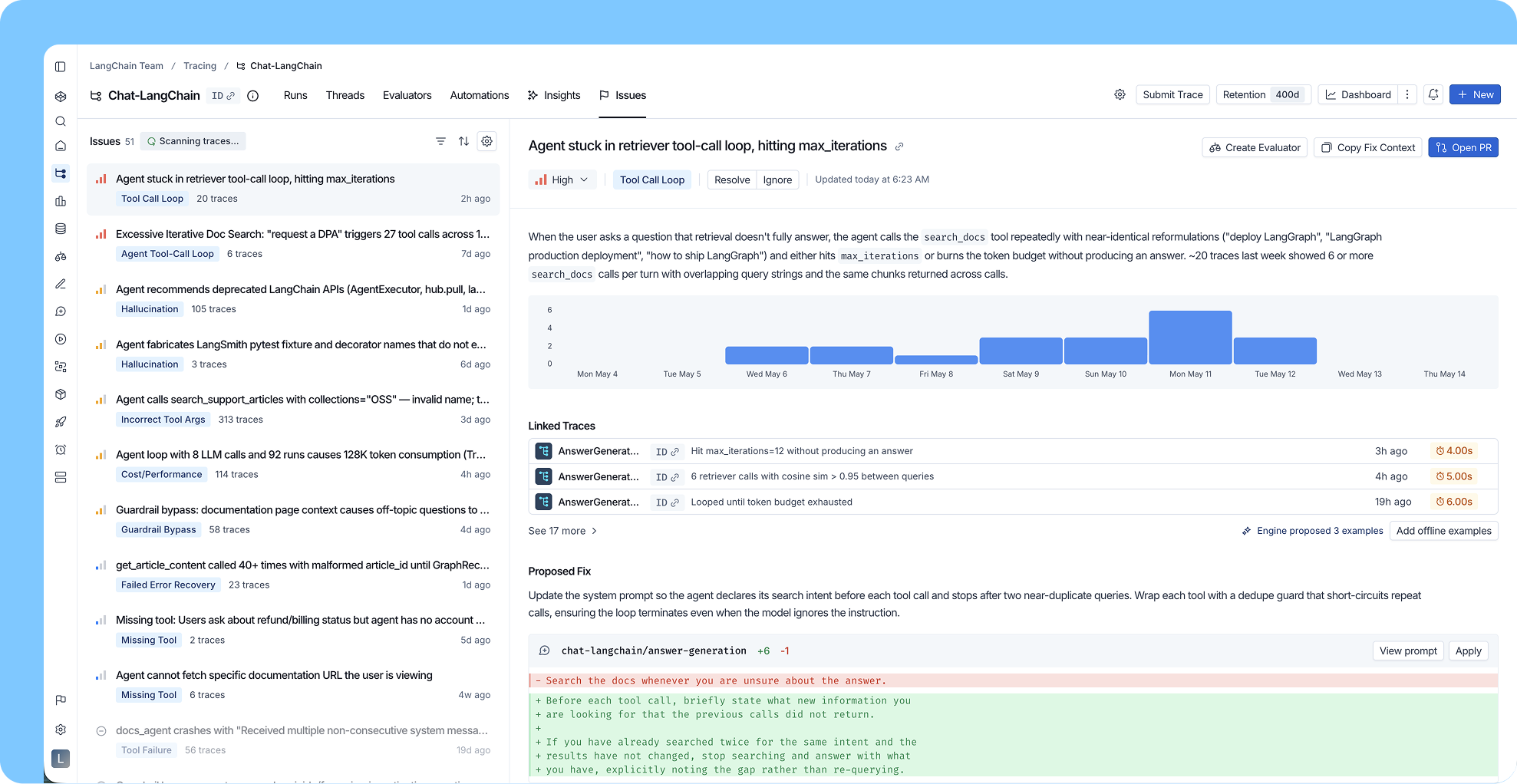
Engine surfaces this as a single named issue, "Agent fails to handle subscription cancellation requests accurately." It shows you the severity (high, affecting 12% of support sessions this week), the timeline (started four days ago, correlating with a recent deployment), and links to the specific traces as evidence.
With your repository connected, Engine reads the relevant code and identifies the root cause. The cancellation tool description is ambiguous, causing the agent to attempt cancellation when users are only asking about their options. Engine drafts a PR with a targeted fix to the tool description.
To keep tracking this behavior going forward, Engine proposes a custom online evaluator scoped to this exact issue, so if the failure pattern recurs after the fix ships, the issue gets resurfaced automatically with updated details.
Engine also pulls the failing traces into a dataset for your offline eval suite, with per-example criteria that define what the correct output should contain. The failures that made it to production become the test cases that keep them out.
That's the full cycle, run autonomously and surfaced for your review. Production signal becomes a clustered issue, then a diagnosed root cause, a proposed fix, and eval coverage.
What Engine does about each issue
For every issue it surfaces, Engine proposes three resolution actions.
Open a PR. With repository access, Engine drafts a targeted code or prompt change and opens it against your repo. You review and merge.
Create a custom online evaluator. Engine proposes an evaluator scoped to the exact problem. If it fires again, the issue gets resurfaced automatically with updated details.
Add to your offline eval suite. Engine pulls the failing production traces into a dataset of ground truth examples, ready to run in your offline eval suite.
Every resolved issue improves your eval coverage along the way. When you confirm a fix, you're also generating an evaluator that monitors performance going forward. Over time, the issues you've already resolved make your eval suite more complete, which makes future improvements more robust.
How Engine works
LangSmith Engine is powered by a deep agent that has access to your trace data, evaluator feedback, and your agent's source code (if connected to your repo).
It monitors traces for several signal types: explicit errors (tool call failures, timeouts), online evaluator failures, trace anomalies (latency spikes, token blowouts, unexpected step counts), negative user feedback, and unusual behaviors like users asking questions the agent wasn't built to answer. When Engine spots a pattern across multiple traces, it clusters them into a single named issue rather than surfacing each failure individually.
LangSmith Engine is built on top of LangSmith's existing tracing and evaluation infrastructure. It uses your existing evaluator results as inputs, so failures your evals catch feed directly into issue detection. When Engine proposes a new evaluator, it's because it detected a gap in your current coverage. When it creates a dataset example, it goes directly into your existing offline eval workflow.
What customers are seeing
Teams like Cogent, Harmonic, and Campfire have already used Engine to resolve issues affecting thousands of traces. They're catching regressions earlier, shipping fixes faster, and spending less time on triage.
We love it so far. Our deepagent traces can contain dozens or hundreds of turns, which makes review and identifying patterns tedious. LangSmith Engine saves our team hours of digging by not only identifying emerging failure modes, but also proactively suggesting evals and code changes to resolve them quickly.
-Austin Berke, Founding Eng @ Harmonic
Where this is going
The agent development lifecycle has been manual for too long, and we're working toward a future where more of it runs continuously without manual triggers, where well-understood issue types resolve without human review, and where the harness gets smarter about your specific agent over time. LangSmith Engine is the first step.
Get started
LangSmith Engine is available now in public beta. Connect a tracing project, optionally connect your repo, and Engine will begin surfacing issues from your production traces automatically.






