

Key Takeaways
- Lyft moved agent development closer to the people who understand customer issues best. By letting ops teams, VoC leads, and product managers define agents through prompts and configuration, Lyft reduced the need for MLEs to manage every iteration.
- A router-based multi-agent architecture helped support complex customer workflows. Lyft uses LangGraph to route rider and driver requests across specialized subagents, with safety checks, state management, and handoffs built into the flow.
- Production quality depends on evaluation, monitoring, and prompt discipline. Lyft uses LangSmith for tracing, dashboards, and LLM-as-a-judge evaluation, but the team found that structured prompt writing became one of the biggest factors in agent reliability.
This is a guest post from our friends at Lyft, where the SCX Data Science and MLE team built a multi-agent customer support system that enables non-technical domain experts to ship AI agents. Led by Akshay Sharma, Machine Learning Engineer. Thank you for your contribution.
TL;DR
By leveraging LangGraph to orchestrate a sophisticated multi-agent system, Lyft has transformed its customer support operations, managing millions of interactions for riders and drivers. Our "self-serve" platform integrates LangGraph’s subgraph architecture with LangSmith’s robust tracing and monitoring tools, empowering non-technical domain experts to develop and refine AI agents independently. This shift has accelerated agent development from roughly six months to just a few weeks, all while upholding high standards through an automated LLM-as-a-judge evaluation system.
Lyft’s Goal: Speeding Up Agent Iteration, Safely
Across numerous categories including account access, damage claims, charge reviews, and earnings disputes, Lyft's AI Assist manages customer support for riders and drivers. Our journey began in 2023, but the process was labor-intensive; developing each AI agent demanded months of dedicated work from Machine Learning Engineers (MLEs) and engineering teams. Although we successfully launched agents for riders and drivers with increasing efficiency, the overall pace remained a significant bottleneck.
By 2026, our existing operating model faced an unsustainable surge in demand driven by new user segments, additional issue types, autonomous vehicle support, and more. The development cycle relied on a slow, iterative loop: domain experts would define workflow behaviors, which MLEs then translated into tool configurations and prompts. This back and forth reviewing traces, flagging problems, and adjusting code required weeks of collaboration for every single agent. Consequently, those with the deepest understanding of customer issues were unable to implement solutions without a technical middleman.
This led us to a pivotal question: Could we empower ops teams, VoC leads, and product managers to construct and refine agents directly using natural language? Our goal was to eliminate the technical intermediary from the daily iteration process to accelerate learning and deployment. Crucially, this shift toward self-service could not compromise our rigorous standards for experience, accuracy, and safety; every agent still had to match the quality of our manually engineered systems.
Architecture: A Multi-Agent System Built on LangGraph
The Router Multi-Agent Pattern
Our system follows LangGraph's router multi-agent architecture. A meta agent acts as a stateful router: it classifies the incoming request and uses Command(goto=...) to dispatch to the appropriate specialized subagent. Each subagent is a full LangGraph StateGraph, registered as a subgraph node in the meta agent.
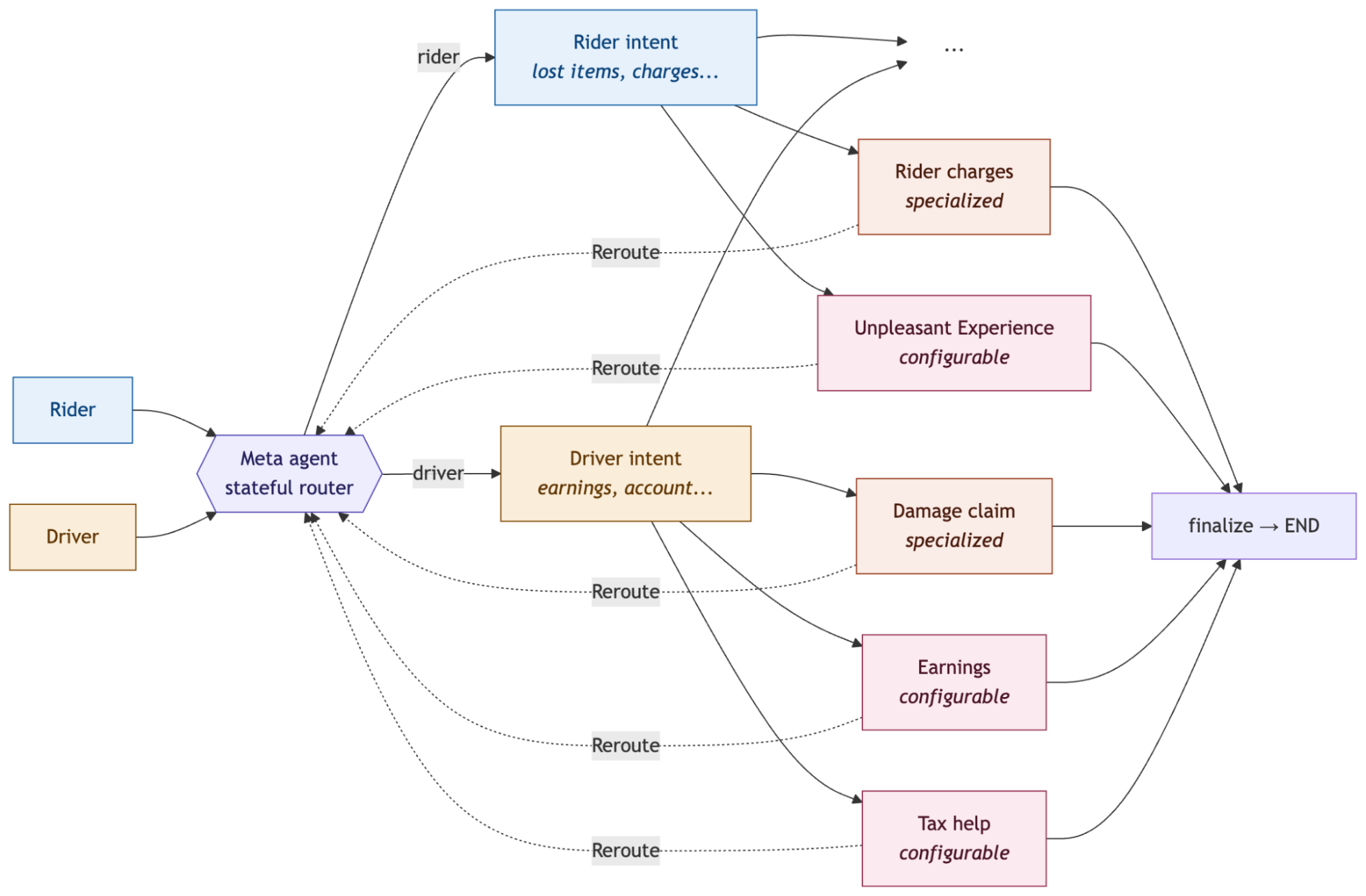
We run separate router instances for riders and drivers. When a rider contacts support, the meta agent routes to the rider_intent subagent, which classifies across rider-specific intents (e.g. lost items, charge disputes, trip issues). For drivers, it routes to the driver_intent subagent, which handles driver-specific intents (e.g. earnings, account access, damage claims). If the intent agent determines during a conversation that the user needs a more specialized agent, it uses Command(goto=..., graph=Command.PARENT) to hand control back to the meta agent, which re-routes to the appropriate specialist, for example, jumping from the driver intent agent to the damage claim agent mid-conversation.
Each subagent, regardless of specialization, follows a consistent node pattern:

This gives us two important properties. First, safety runs in parallel at every turn, malicious intent detection and safety issue detection execute concurrently via LangGraph's Command(goto=[...]) fan-out before any LLM reasoning happens. Second, subagents are modular and independently deployable adding a new agent means defining a new subgraph and registering it with the meta agent.
Specialized vs. Configurable Agents
We have two categories of agents:
Specialized agents are hand-built by MLE for complex, high-stakes workflows. Our damage claim agent, for example, assists with image processing, fraud detection, multi-step classification, and automation calls too complex for a low-code approach.
Configurable agents are the self-serve layer. They're initialized at runtime from JSON configuration stored in our internal config service, with prompts pulled from LangSmith's Prompt Hub. A domain expert writes the prompt following our structured template (role, scope, workflow phases, content guidelines), and the ConfigurableAgent class handles the rest: graph construction, tool binding, safety gates, and state management.

# Configurable agents are loaded dynamically at startup
for configurable_agent in load_configurable_agents():
self.configurable_subagents[configurable_agent.config.intent] = configurable_agent
# Each one registers as a subgraph in the meta agent
for configurable_subagent in self.configurable_subagents.values():
graph_builder.add_node(
configurable_subagent.config.intent,
configurable_subagent.get_state_graph()
)
graph_builder.add_edge(configurable_subagent.config.intent, "finalize")This means a product manager can define a new agent, such as for driver tax questions, by writing a prompt and a JSON config. No MLE code changes are required. The platform handles graph construction, tool execution, checkpointing, tracing, and safety.
State Persistence with DynamoDB
Multi-turn conversations require a durable state. We built a custom DynamoDBSaver that implements LangGraph's BaseCheckpointSaver interface, giving us persistent conversation state across turns without any in-memory assumptions. Each checkpoint stores the full graph state, execution metadata, and parent checkpoint references enabling conversation replay, debugging, and state inspection in production.
LangSmith: From Tracing to Production Monitoring
Tracing Every Agent Turn
Every agent invocation across all environments (development, staging, production) is traced to LangSmith with LANGSMITH_TRACING=true. Each trace captures the full graph execution: which nodes ran, what the LLM saw, which tools were called, token usage, and latency at every step.
We enrich traces with custom metadata (user type, agent name, intent, conversation ID) using a utility that builds runtime metadata for filtering:
# Metadata flows through to LangSmith for filtering and debugging
tags = build_langsmith_metadata(
agent_name=self.name,
user_type=context.user_type,
interaction_id=context.interaction_id
)This has been invaluable. When a driver reports a confusing response, we can pull the exact trace, see every node's input/output, identify whether the issue was in intent classification, tool execution, or the final LLM response, and fix it within hours.
LLM-as-a-Judge Evaluation Pipeline
Before any agent rolls out to 100% of traffic, it must pass our evaluation pipeline. The process:
- Small production rollout (5–10%) — the agent serves real traffic at low volume.
- Sample production traces — we capture real conversations as evaluation datasets.
- Run LLM-as-a-Judge evaluators — using a shared judge prompt template from LangSmith's Prompt Hub, extended with agent-specific metrics.
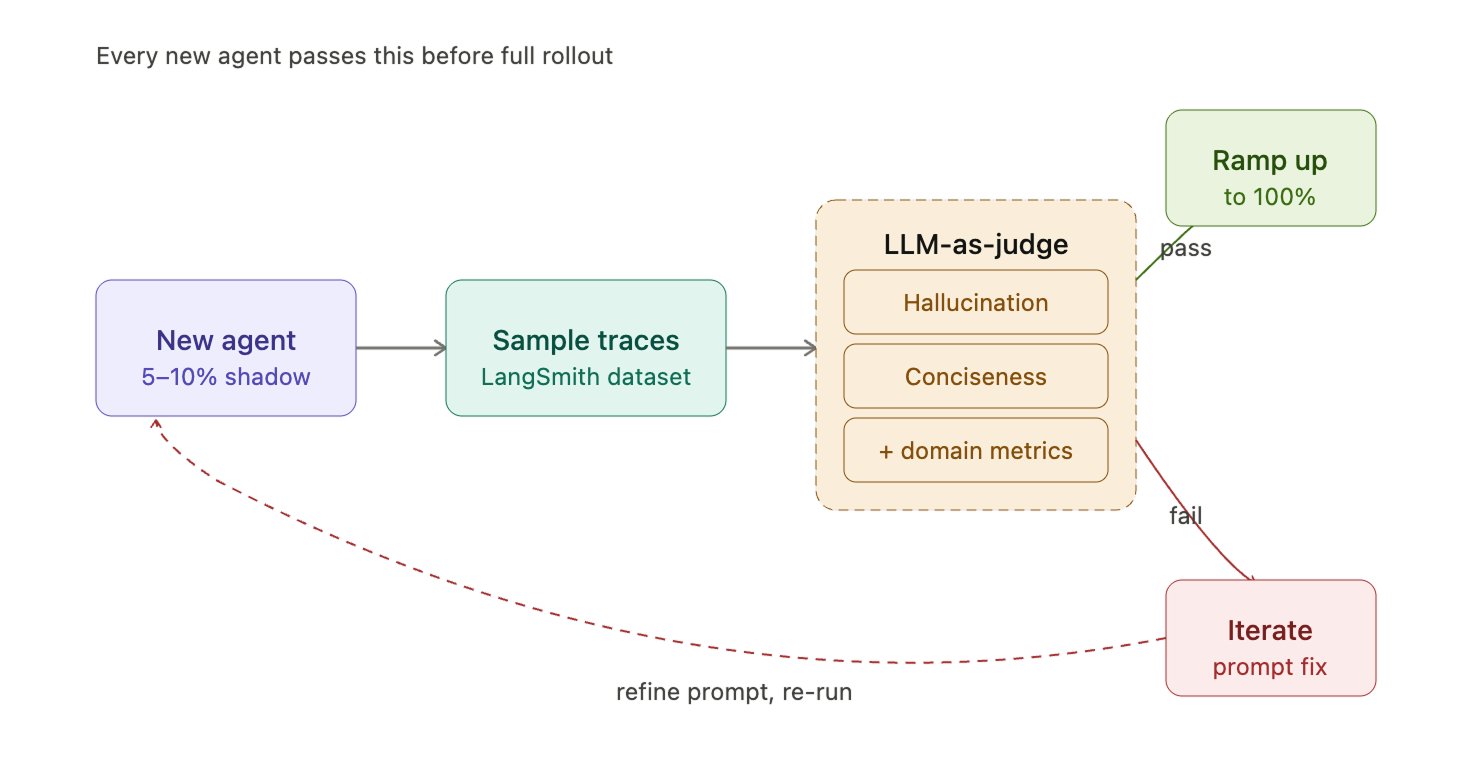
Our baseline evaluation metrics (applied to every agent):

We then add some domain specific metrics for each specialized agent. For example, the core earnings agent checks whether the agent followed or deviated from the relevant policies or used any illogical or inconsistent reasoning.
The evaluators run automatically on production traces using LangSmith's multi-turn evaluator, configured with thread filters (e.g., run name is ride_earnings) and sampling rates that start high during initial rollout and taper as confidence grows.
Production Monitoring Dashboards
Every agent in production has a cloned LangSmith monitoring dashboard tracking:
- Run volume and error rates — are we seeing unexpected spikes or failures?
- p50/p95 latency — is the agent responding fast enough for real-time support?
- Token usage — are costs within budget?
- Tool call success rates — are external API integrations healthy?
- LLM-as-a-Judge scores over time — is quality trending up or down?
We also set up PagerDuty alerts triggered by LangSmith metrics. If the error rate exceeds 5% or p95 latency crosses 10 seconds over a 15-minute window, the on-call engineer is paged automatically.

An example chart of error rate by tool (part of monitoring dashboard in production)
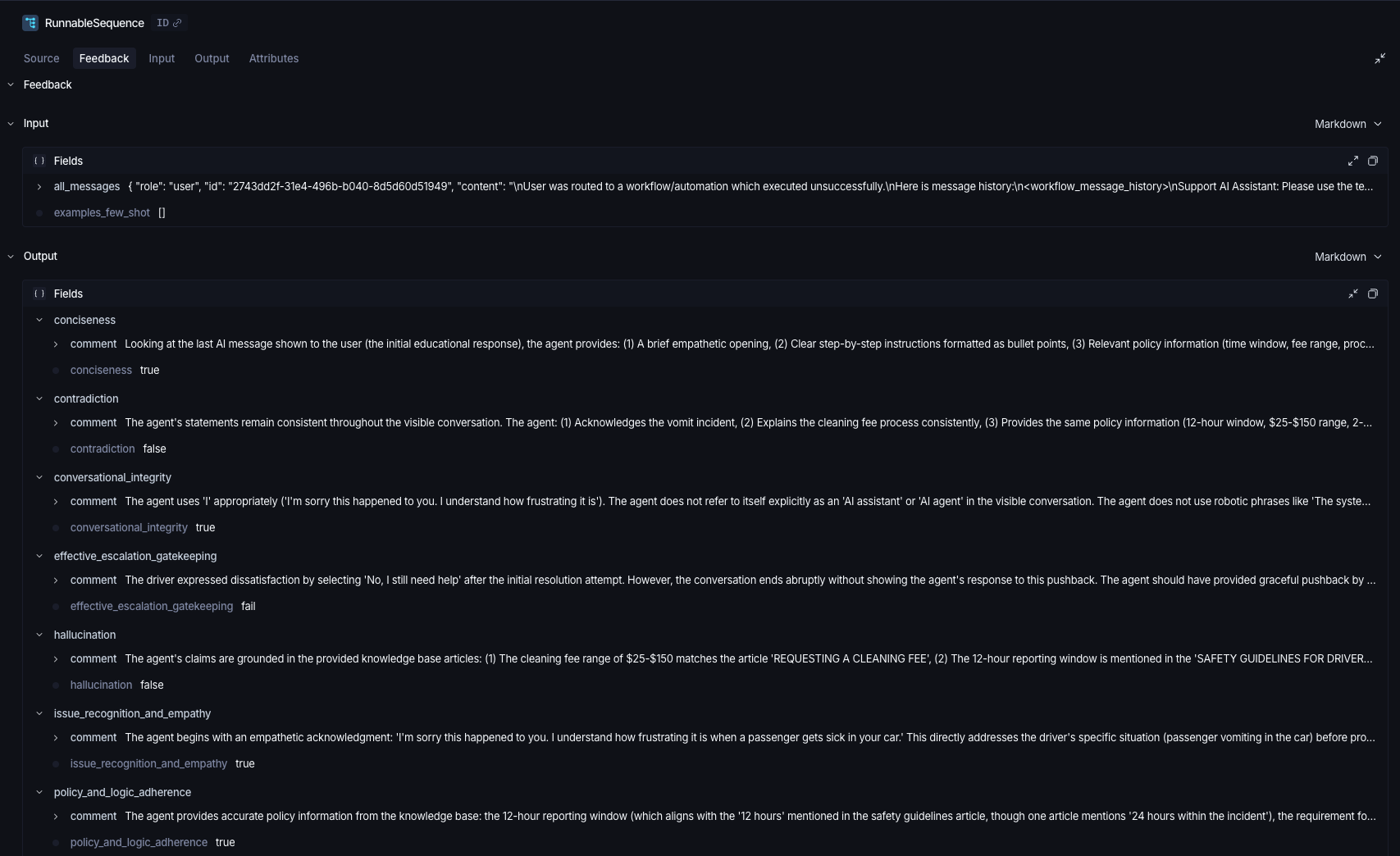
LLM Judge evaluation with custom (agent specific) metrics running in production. Tip: Use binary outputs (True/False or Pass/Fail) instead of scores which are inaccurate and non actionable.
The Hard Lesson: Prompt Quality Is the Bottleneck, Not Infrastructure
When we first opened agent building to non-technical teammates, we assumed the hardest part would be the platform itself getting tool bindings right, handling edge cases in the graph, and managing state. We were wrong.
The hardest part was prompt quality. Domain experts knew their issue types deeply but didn't always know how to translate that knowledge into instructions an LLM would follow reliably. We saw agents that handled the happy path beautifully but fell apart on edge cases. A prompt might define what the agent should do when a driver disputes a fare, but say nothing about what happens when the driver changes topic mid-conversation. Or the tone section would say "be empathetic" without specifying what that actually means so the LLM would interpret it differently every time.
The failure modes were surprisingly consistent: missing out-of-scope definitions (so the agent tried to answer questions it had no tools for), ambiguous branching logic (phases with no explicit entry or exit conditions), and vague content guidelines that sounded good on paper but gave the LLM too much room to improvise.
We attacked this on two fronts.
First, a structured prompt writing framework. We created a template with five required components: identity (who is this agent, what user type, what topic area), primary objective (concrete verbs, not vague "help" or "handle"), scope (both in-scope AND out-of-scope with explicit routing actions), phased workflow (numbered steps with entry conditions, branching for every if/else, and a terminal action for every phase), and content guidelines (concrete do/don't rules with example phrases, not abstract principles). We paired this with a review checklist that every prompt must pass before activation, things like "does every phase have an exit?" and "are there instructions for what to do when a tool is unavailable?"

Second, automated prompt validation. We're building a Git-backed prompt linting pipeline that runs before any prompt reaches production. When a domain expert finishes writing a prompt in our builder UI, it opens a pull request against our config repository. A CI pipeline then runs two layers of checks: fast static rules (catching malformed template variables, duplicate intent slugs, spelling errors) followed by LLM-powered rules that detect prompt injection vulnerabilities, contradictory instructions, and structural dead-ends where a conversation flow has no way out. All violations block the merge. The author gets inline feedback in the UI and can fix issues themselves without pulling in an MLE.

The key insight behind all of this: treat prompts like product specs, not code comments. The more explicit the prompt, the more consistent the agent. And the earlier you catch quality issues, ideally before a single real customer ever sees the output, the faster the whole system improves.
Results
Since launching the self-serve agent platform:
- Agent development time: Reduced from ~6 months (first driver agent) to ~2 weeks for new configurable agents.
- Agent coverage: A growing number of configurable agents in production covering multiple issue types, alongside several specialized agents.
- Evaluation coverage: 100% of production agents have automated LLM-as-a-Judge pipelines running on live traces.
- Quality: Hallucination and contradiction rates have decreased by 20% with hallucination guardrails we have set up based on Langsmith evaluation metrics.
- Operational efficiency: Many non-engineering team members are now building and iterating on agents independently.
- AI Resolution Rate: Up by 16% since we launched a few agents using our self-serve platform.
What's Next
We're looking at several areas to push this platform further:
- Completing the prompt linting pipeline — the Git-backed CI validation described above is actively in development. Once fully rolled out, every configurable agent prompt will pass through automated static and LLM-powered checks before it can reach production, with zero manual MLE review needed for common errors.
- Mocking and simulation infrastructure — building a simulation layer that lets agent builders test against synthetic conversations and mocked tool responses before deploying to real traffic, dramatically shortening the feedback loop for new agents.
- Pairwise evaluation — using LangSmith's Pairwise Annotation Queues to A/B test prompt revisions with human reviewers before shipping.
- Expanding to more geographies and user types — bringing the platform to Freenow customers in Europe and autonomous vehicle support scenarios.
- Deeper eval automation — moving from sampled evaluation to continuous scoring on all production traces, with automatic prompt degradation alerts.







