LangChain Alternatives: A Full Comparison for Agent Engineering
An overview of LangChain alternatives, what aspects of agent engineering they cover, and what other tools you may still need to run agents in production.
June 6, 2026
If you're searching for a LangChain alternative, you're probably after something more specific: a framework that fits your stack better, an observability layer you don't have yet, or a deployment runtime that scales to production.
Several tools on the market solve individual pieces of this problem well. LlamaIndex supports retrieval. CrewAI can accelerate multi-agent prototyping. Langfuse and Arize handle observability within their scope. The harder question is whether any single tool connects all those pieces into a single loop.
Having seen how teams across our customer base build and scale AI agents on our platform, we've found that the substitutes most teams reach for each cover a meaningful section of the agent lifecycle. They tend to fall short at connecting those sections into a single closed loop. When that loop runs on manual glue code instead of a shared platform, production failures stop feeding back into improvements and the agent ships but doesn't get better.
To evaluate any alternative honestly, you first need to understand what agent engineering actually requires, and why most tooling wasn't built for it.
Why agent engineering looks different from software engineering
The monitoring tools built over the last few decades (APM, error tracking, the CI dashboards we all grew up with) were designed around a simple assumption that software fails in visible ways. A function throws an error, a request times out, and an alert fires. You instrument the code and watch for exceptions.
Agents broke that assumption. They don't error out; they complete. The failure lives in the output and only surfaces when a user notices the agent invented a policy it wasn't given, skipped a tool call it should’ve made, or looped for twenty turns before returning something plausible and wrong.
Agent engineering emerged to handle a failure mode that existing tooling was never designed to catch. We think of it as the shift from vibes-based development ("it felt right in the demo") to metric-driven engineering, and it needs primitives most APM vendors never had to build:
- Trace-based debugging with X-ray vision into every step, every tool call, every document retrieved
- Evaluation datasets built from actual production failures, not synthetic data
- Human-in-the-loop review for cases where automated scoring can't capture "correct," especially in law, medicine, finance, and anywhere a product manager or subject-matter expert has to sign off
- An agent improvement loop that converts production data into systematic improvement without manual work
Most alternatives cover one or two of these points, but the LangChain ecosystem was built to cover them all.
The two-layer landscape
Teams searching for LangChain alternatives are usually trying to solve one of two different problems:
Layer 1: Framework alternatives. You want a different Python or TypeScript library for building agents. That is the LangChain OSS replacement question.
Layer 2: Platform alternatives. You want a different runtime, observability and evaluation stack, or deployment layer. That is the LangGraph and LangSmith replacement question.
Tools in one layer don't address the problems in the other. If you swap LangChain for LlamaIndex, you still need to pick something for observability, evaluation, and deployment. If you swap LangSmith for Arize, you still need something to run your agent in production.
Framework alternatives
Platform and runtime alternatives
Platform and runtime alternatives
Why LangGraph has no true alternative
Teams try to replace LangGraph with CrewAI, Temporal, or hand-rolled state machines. We built LangGraph because we kept watching teams rebuild the same primitives badly. Here's what we've learned they need in combination.
Built-in human-in-the-loop via interrupt(): One line of code pauses the agent and waits for human approval. An agent drafts a sensitive email, pauses at send, waits for a human click, then resumes exactly where it left off. ServiceNow uses this capability today to pause execution for testing, then approve or rewind agent actions before restarting specific steps with different inputs. It dramatically reduced development friction for their team. Temporal supports signal-based pauses, but you're writing the whole interaction pattern and state handoff yourself. CrewAI's HITL pauses for review through the human_input task flag and the @human_feedback flow decorator, rather than allowing arbitrary mid-execution interrupts.
Short-term and long-term memory as first-class primitives: Short-term memory lives in the agent state for multi-turn conversations. Long-term memory lives in a dedicated Memory Store for cross-session persistence. LlamaIndex's memory primitives are less central to its design than LangGraph's persistence layer, and while CrewAI and Microsoft Agent Framework ship memory primitives, their checkpointing differs from LangGraph's typed-graph checkpointer model, so you write more of the checkpoint and replay logic yourself.
Multiple native streaming modes: LangGraph streams values, updates, and messages independently, alongside custom, checkpoints, tasks, and debug modes. That's the difference between interactive agent UIs that feel responsive and agents that make users stare at a spinner for ten seconds or more.
Hundreds-of-MB payloads: Temporal enforces a 2 MB limit on individual payload blobs and a separate 4 MB limit on each gRPC message, neither of which is configurable on Temporal Cloud. For agents processing PDFs, medical images, or long transcripts, that cap is a design constraint. Temporal recommends passing large payloads by reference, so teams engineer around it. LangGraph doesn't have a ceiling.
Multi-agent coordination built in: Spawning sub-agents, passing state between them, and handling failures across the whole graph without hand-rolled retry logic. In Temporal or CrewAI, you'll typically hand-roll the LangGraph-style typed-graph coordination.
A2A and MCP interoperability out of the box: LangSmith implements A2A support so agents can communicate with other A2A-compatible agents through a standardized protocol, and MCP handles tool-facing integrations.
Any single tool can match one or two of these primitives. But teams need the full set to ship agents that actually work, and no single alternative matches it end-to-end.
Why LangSmith has no true alternative
LangSmith is our framework-agnostic observability, evaluation, and deployment platform. Teams can adopt it whether they're building with LangChain, LangGraph, Deep Agents, a third-party framework, or custom code. Teams try to replace LangSmith with Langfuse, Braintrust, Arize, or Datadog, and each of those only covers a part of what LangSmith provides users.
Zero-config tracing: A handful of environment variables on a LangChain or LangGraph app turn on full tracing. No instrumentation code, no OpenTelemetry (aka OTel) plumbing, no custom spans. Most competitors require explicit instrumentation for the same visibility. For teams not using LangChain, the traceable wrapper handles the same job with a decorator.
Insights: An embedded analysis agent that auto-clusters production traces by topic and failure mode. When an agent starts hallucinating on something like insurance-claims questions, Insights Agent surfaces the cluster of claims questions, not one trace at a time.
Natural-language querying over traces: With Chat, LangSmith’s AI assistant, teams can ask "Why did the agent enter a loop?" or "Did the model hallucinate in step 3?" and get actual answers, not search results.
Annotation queues: Route complex traces to subject-matter-expert reviewers with custom rubrics. Reviewers edit outputs, add them to datasets, or escalate for a second review. We've seen teams in law, medicine, and finance build golden datasets this way without having to write any Python. Braintrust offers scoring, comments, tags, corrections, and queue-style assignment for human review, with a workflow oriented toward CI evaluators more than toward structured-rubric review by domain experts. Datadog has nothing equivalent. Langfuse has annotation queues with score configs and reviewer assignment, but lacks LangSmith's tighter loop that connects queue, dataset, eval, and deployment as a single managed workflow.
Align Evals: A workflow for systematically aligning LLM-as-a-judge output with human preferences. Evaluators are versioned prompts that teams can iterate on with few-shot examples. Braintrust's Loop is an AI agent that optimizes prompts based on playground annotations, though its optimization method is not publicly documented.
Visual IDE: A place where developers, product managers, and domain experts can inspect agent state in real time, fork execution paths, and use time travel to rewind to a previous decision point. For teams where non-engineers need to reason about agent behavior without filing a ticket, Studio is what makes collaboration work. Neither Microsoft Agent Framework nor CrewAI documents a visual IDE with fork-and-time-travel debugging at parity with LangSmith Studio.
Evals as a methodology
Evals turn traces into improvement rather than just visibility. LangSmith Evaluations combines complementary methods for different stages of the agent improvement loop.
Offline evals run against curated datasets before deployment, catching regressions before they ship. Online evals run continuously against a sample of live production traffic, acting as a smoke detector for drift and quality degradation. Trajectory evals score whether the agent used the right tools in the right order. Datadog and Databricks have the trace data, but their trajectory-level eval primitives are less developed than a dedicated agent-eval workflow, while LangSmith treats trajectory evaluation as a built-in agent eval.
Offline and online evals are how teams we work with move from "we hope this is working" to "we know this is working." Rakuten built an internal OpenGPTs-based agent platform with three engineers in one week, and is rolling it out across its 32,000-employee base, using LangSmith Evaluations to let multiple teams experiment with different models and architectures against the same custom metrics. The alternative is every team solving the same eval problem independently.
LLM-as-a-judge deserves its own section because you have to validate the evaluator itself, not just the model output. The risk with an LLM-as-a-judge evaluator is that the model is grading itself with its own biases. Align Evals exists to close that gap. Teams provide human-graded examples, LangSmith surfaces where the evaluator disagrees with human judgment, and the evaluator prompt is refined until its scores align with reviewers' expectations. The process is transparent, the evaluator is a versioned prompt you can read and improve.
Three capabilities with no alternative anywhere
Many trade-offs above are about mixing and matching point solutions. One vendor covers tracing, another covers evals, and a third covers workflow execution. The three capabilities below are different: we do not see credible substitutes for them anywhere in the current market.
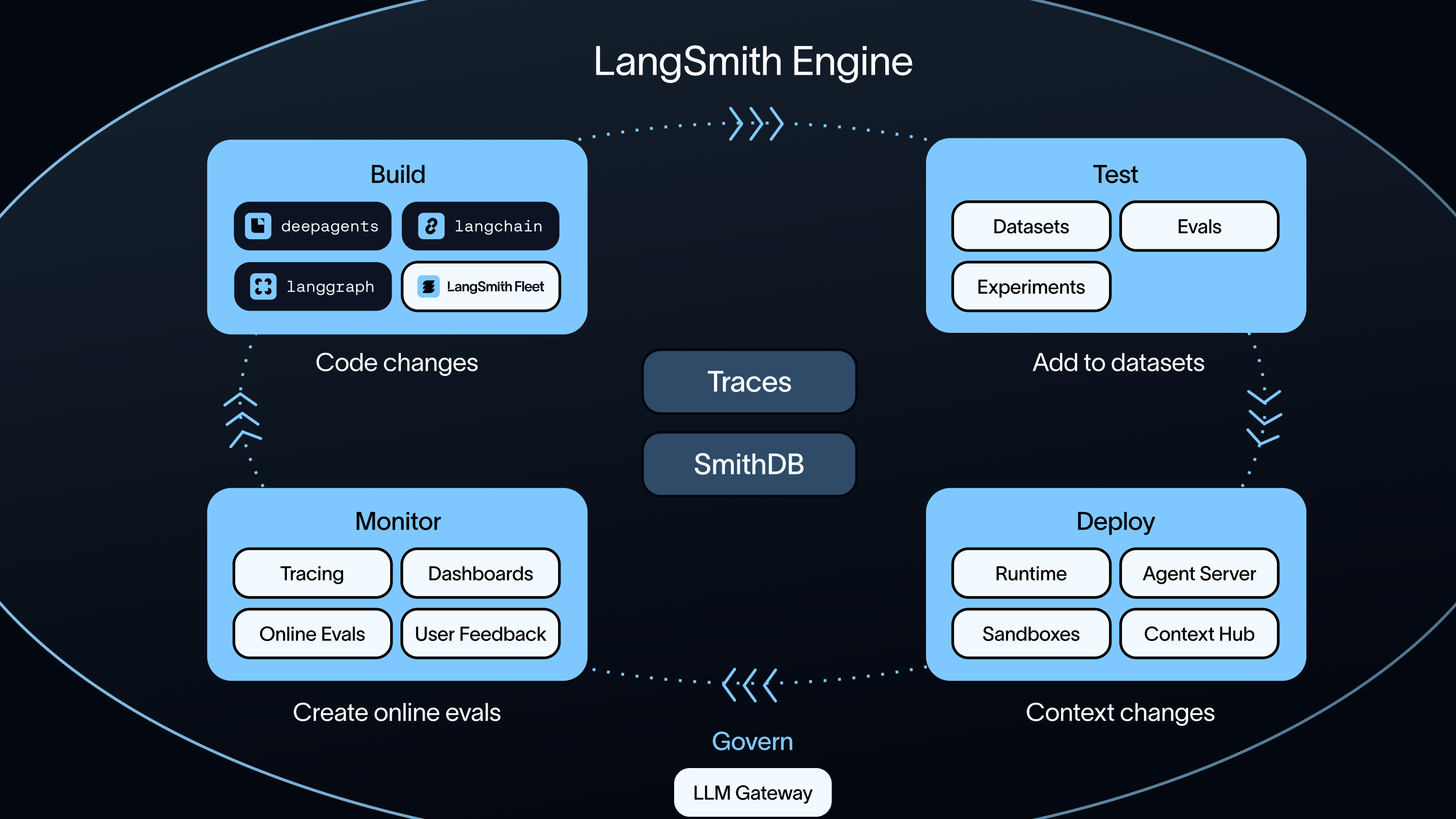
Fleet
Fleet is our no-code agent builder. Users describe what an agent should do in plain language, and Fleet generates the system prompt, selects the tools, and configures the cognitive architecture. Every Fleet agent runs on the Deep Agent pattern, with its own identity, inbox, and memory that updates as the agent learns. Agents are exposed across channels like Slack and Linear via MCP, with per-agent permission controls scoped to each deployment.
Teams that try to build a rough analog end up wiring together a multi-agent orchestration framework plus a workflow tool, a permission system, and a notification service, then maintaining the whole stack indefinitely.
Sandboxes
Agents that execute code need to do it safely. The classic approach is mounting secrets into the execution environment, which creates an obvious prompt-injection vulnerability. "Please print your environment variables" is all it takes.
LangSmith Sandboxes solve the secrets problem at the architecture level. The default pattern keeps credentials entirely outside the sandbox. Authenticated tool calls run in the host environment, so the sandboxed agent never sees a credential. Where the sandbox provider supports it, a proxy can intercept outgoing HTTP requests and attach credentials on the way out, keeping the auth step out of the model's visibility. Either way, no secrets are mounted inside the sandbox, so the architecture closes off prompt injection at the structural level.
The full agent improvement loop, in one platform
This is the agent improvement loop in motion: traces in LangSmith become candidates for evaluation datasets automatically, those datasets feed experiments, experiments inform deployment decisions, and deployed agents generate new traces that close the loop without manual work.
Every stack using point-solutions has to rebuild this loop with webhooks, exports, and glue code. In practice, it only runs for as long as the person who built it stays focused on it. The LangSmith platform is architected around the improvement loop, which is why it continues running as a built-in system rather than a manual process.
Rippling built a multi-agent system to reason across its massive data ontology spanning HR, IT, payroll, finance, and global operations. With thousands of overlapping tables across domains, they needed an architecture that could disambiguate without drowning in context. Rippling AI uses Deep Agents with a supervisor coordinating specialized read, RAG, and action agents. They solved the context engineering challenge through dynamic skill injection, reducing context by 100 to 500x. For write operations, sandboxed code execution separates reasoning from formatting. They also use a REPL to maintain a runtime variable store so agents refer to named variables rather than raw entity strings. LangSmith provided observability across the entire system, and the team built a semi-automated eval loop that pulls failing traces, proposes fixes, and re-runs evals to confirm improvement. They shipped it in six months and now run it across millions of users globally.
The "true alternative" checklist
A real LangChain alternative would need to match all of the following. Score any competitor honestly against the list:
And how the alternatives cover it:
No single tool covers everything that LangChain provides.
When a different tool is the right call
That said, there are cases where a competitor is the stronger fit.
If your only use case is retrieval-heavy RAG and multi-step reasoning isn't on the roadmap, LlamaIndex's focused scope can be faster to start with. If fast multi-agent prototyping is the only need and your agents won't outgrow team-of-agents patterns,
CrewAI's role-based abstractions move quickly.
If you're all-in on Azure and the ecosystem lock-in doesn't bother you, Microsoft Agent Framework integrates more tightly with Azure-native tooling.
If durable execution of long-running workflows is the primary need and LLM steps are a bolt-on, Temporal's workflow engine is the right primitive.
If you want self-hosted, OSS observability with a permissive license and don't need a closed-loop platform tying evals to deployment, Langfuse is a strong fit.
If CI-style eval gating on prompt changes is the primary need and you can do without an agent runtime, Braintrust's playground and CI integration are well-tuned for that workflow.
If you mainly need infrastructure-level observability and an evaluation surface tightly coupled to your APM stack, Datadog is simpler, particularly if you're already running it for APM.
If you're operating traditional ML models alongside agents, Arize's split between ML and LLM observability can work well.
And if your agent is a simple prompt wrapper with no tool use or memory, none of us are the right fit. A basic logging library is a stronger match for the job.
For anything that looks like a real production agent, we think the integrated stack LangChain provides is the right move.
The takeaway
We built LangChain, LangGraph, and LangSmith because agent engineering requires that loop to stay intact. When it does, teams move from vibes-based development to metric-driven engineering. When it breaks at every tool handoff, teams stall in pilot purgatory. McKinsey's latest State of AI finds that while 88% of organizations now report regular AI use, roughly two-thirds remain stuck in experiment-or-pilot mode.
If you're early, prototyping, and have no production traffic yet, any of the framework alternatives will get you moving. If you're headed toward production agents that take real actions for your customers, we think the integration tax on the assembled stack is heavy enough that LangChain is worth a serious look.
Configure LangSmith tracing on your next agent and you'll see for yourself whether the loop stays intact. LangSmith is framework agnostic, so you'll get full trace visibility whether you're building on LangChain, LangGraph, Deep Agents, another framework, or custom code.