LangSmith vs Braintrust: Which AI Agent-Native Platform Fits Your Stack?
Compare LangSmith and Braintrust to see how a complete agent engineering platform differs from an evaluation-focused tool.
June 6, 2026
LangSmith is a framework-agnostic platform that supports the full AI application lifecycle, from development and debugging to evaluation, monitoring, and continuous improvement. While other tools focus mainly on evals, LangSmith ties each stage together into a single loop that helps your team ship reliable agents faster.
With LangSmith, you can build, observe, evaluate, and deploy in one place. Production traces flow directly back into your evals so improvements compound over time.
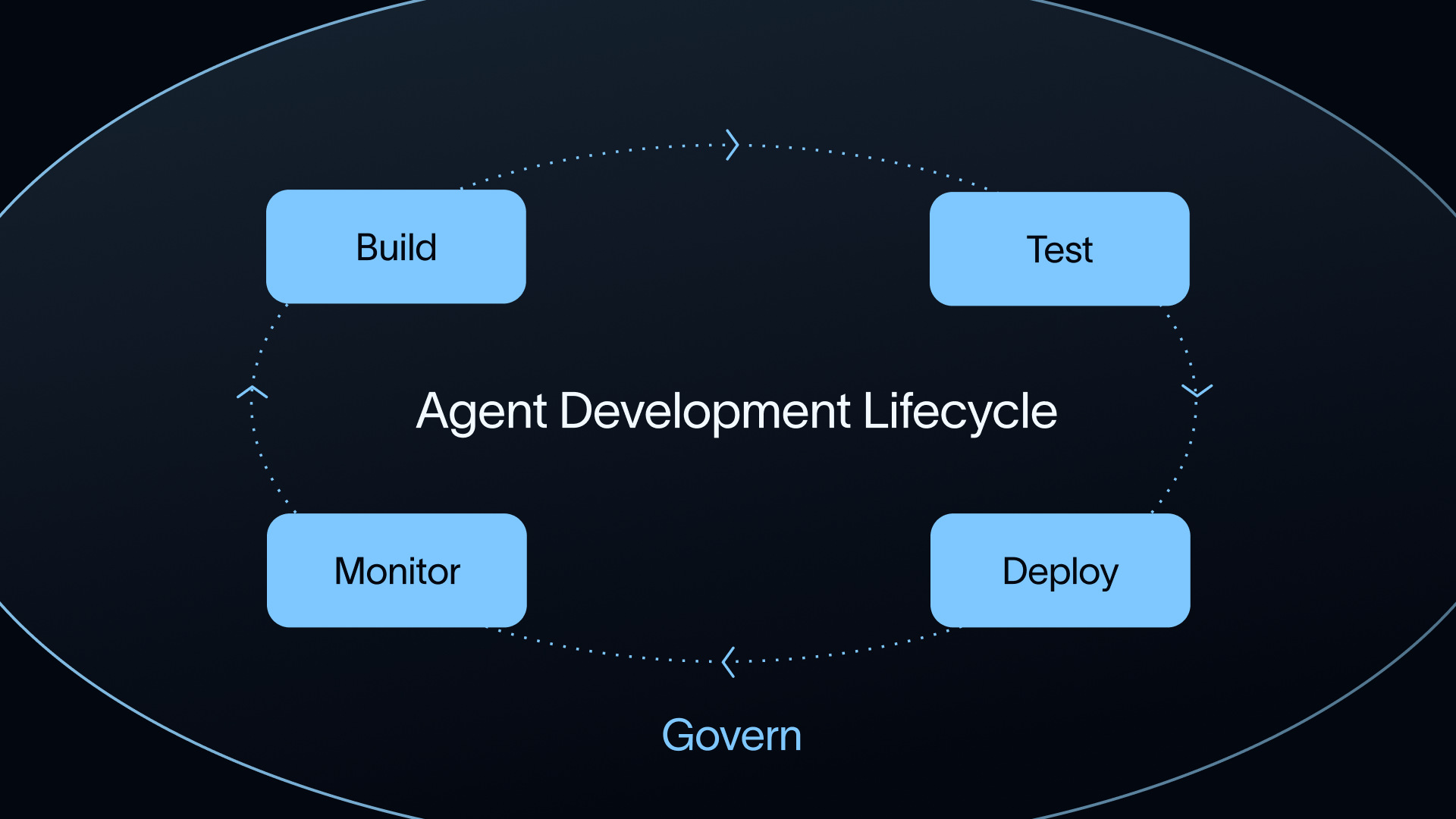
What sets LangSmith apart from Braintrust?
Braintrust is a solid fit for teams focused on structured evaluation workflows and prompt iteration. As your AI agents enter production, you want a platform built for the complex behavior of agents: one with multi-turn threads, eval calibration to human preferences, and automated analysis of user behavior.
LangSmith is a framework-agnostic platform for LLM applications or AI agents. While it works alongside Deep Agents, LangGraph, and LangChain framework it also works with any other stack you choose.
Where Braintrust reaches its limits
Braintrust is a capable eval platform. But limitations surface as your team moves deeper into production.
- Limited automation: Braintrust supports only export, webhook, and data retention automations. There's no native trace-to-dataset routing or trace-to-annotation-queue automation, meaning teams must manually triage production failures rather than letting rules-based routing handle them.
- No native multi-turn conversation evaluation: Braintrust has no multi-turn context or multi-turn evals out of the box. Teams work around this by linking traces with metadata, then concatenating them into message lists. That approach does not hold up for production chat agents and copilots.
- More engineering effort for multi-step agent evals: Community discussions describe Braintrust as a strong fit for teams building their own eval pipeline. Wiring it across multi-step agents takes more custom work. One user reported it was harder to use for full agent testing and felt less modular.
- Eval-first positioning: Braintrust's focus is specific to evals and prompts. They deliver strong signals for prompt and workflow improvement, but the platform isn't built around the full agent lifecycle of capturing agent data, running systematic experimentation, and turning insights into a repeatable flywheel. It’s "simulation and evaluation focused."
- No managed deployment infrastructure: Braintrust focuses on eval and observability. Teams must deploy agents separately using their own infrastructure.
Why choose LangSmith over Braintrust?
Each limitation above aligns with a capability built into LangSmith. The platform is designed around the full agent lifecycle, from evaluation to production deployment.
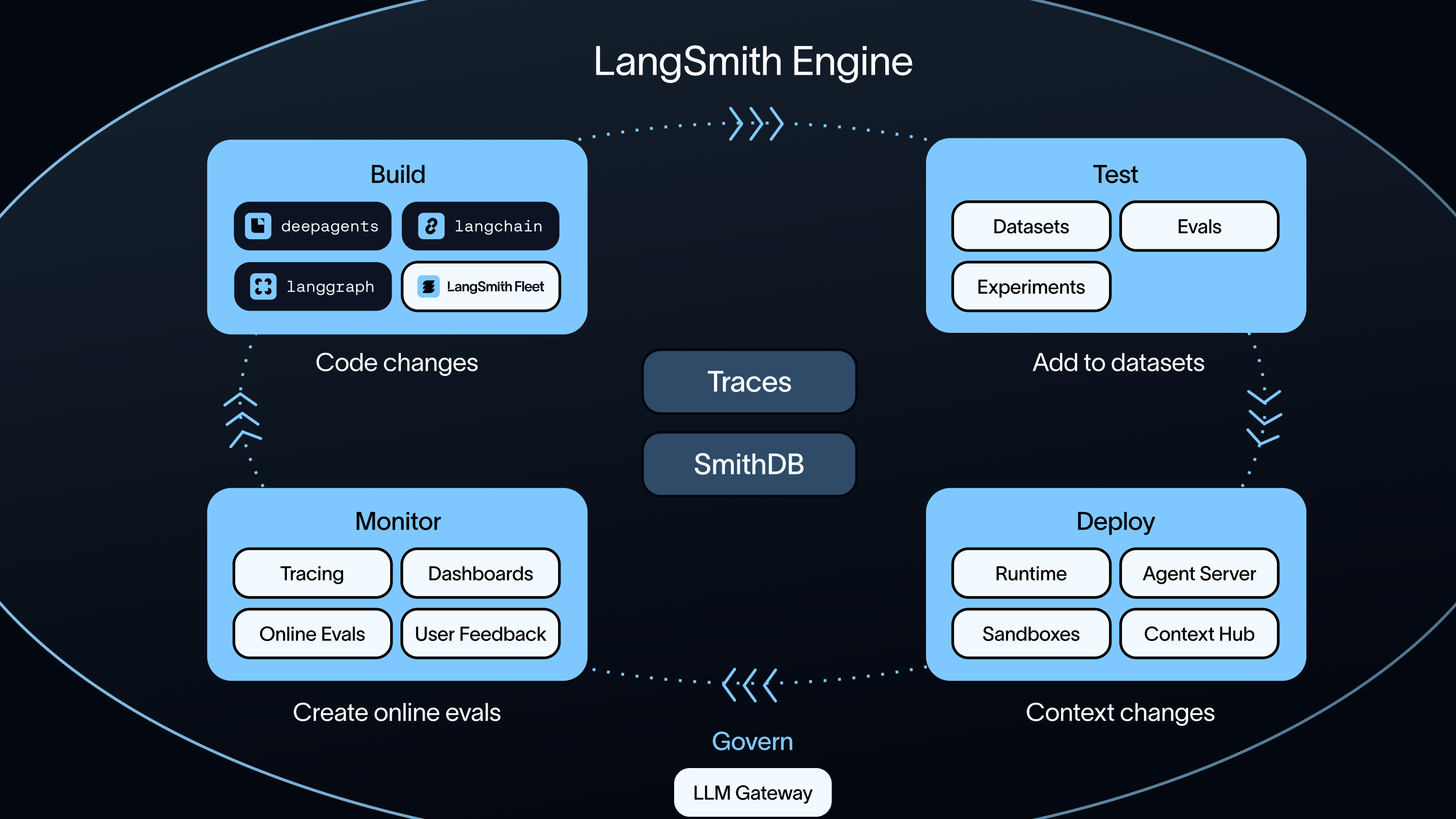
Annotation queues go beyond scoring. Reviewers can revise outputs, add traces directly to datasets, run pairwise comparisons, and escalate items to additional reviewers. Braintrust's review workflow is score-only, with no downstream actions or dataset editing.
LangSmith Deployment provides managed infrastructure for long-running, stateful AI agents built with LangGraph. It supports persistence and task queues, including human-in-the-loop workflows.
Align Evals helps you calibrate LLM-as-judge scorers against human feedback, so automated evaluations reflect what your team actually cares about. Braintrust has no equivalent, so teams rely on ad-hoc Loop workflows or manual judge prompt iteration.
LangSmith helps teams understand agent behavior at scale. Insights automatically categorizes production traces, so you can see usage patterns, common behaviors, and failure modes without manual review. This makes it easier to understand what users ask your agents, where agents fail, and what to prioritize next. Braintrust's Loop agent supports ad-hoc analysis, but it does not provide automated categorization or structured insight reports.
With LangSmith Engine, your production traces are clustered into prioritized issues automatically. Engine suggests a PR for a fix, and creates your offline evals automatically so the regression doesn’t happen again. Engine turns production failures into regression tests automatically.
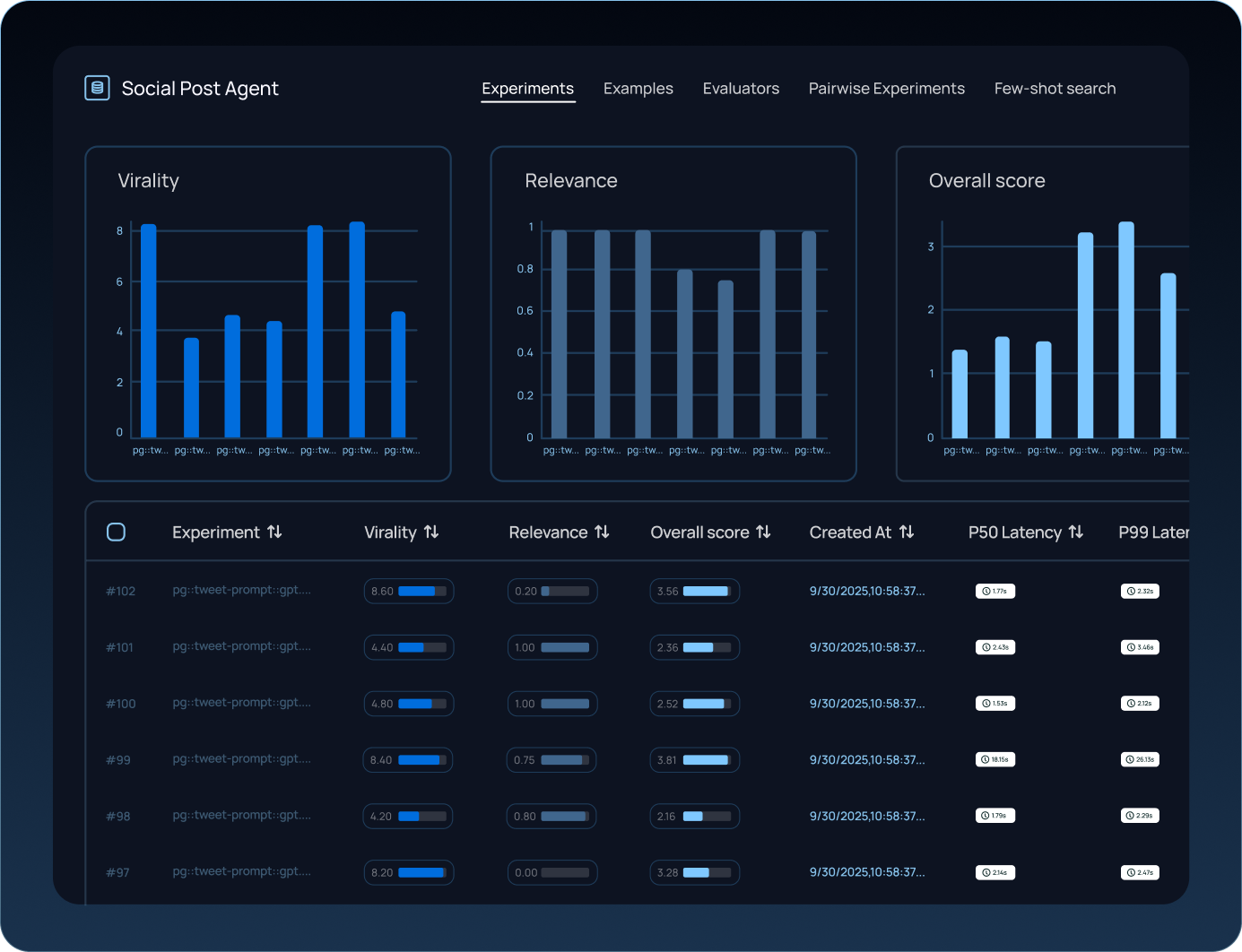
Production traces that power your evals
Braintrust's evaluation results page documents no statistical confidence or significance concepts. When you run an experiment in Braintrust, you see score changes without knowing if those changes are meaningful.
LangSmith closes that gap with the data flywheel. Production traces flow into datasets. Those datasets power evals that drive measurable improvements.
We built offline evals to run against curated datasets pulled directly from production trace data. You define scoring criteria and run experiments with statistical grounding.
Online evals run continuously against live production traffic. You catch regressions in real time rather than discovering them in post-hoc reviews.
LLM-as-a-judge evaluators score outputs at scale using criteria you define. We pair automated scoring with human review through annotation queues, so engineers validate alongside domain specialists. PMs contribute their perspective too.
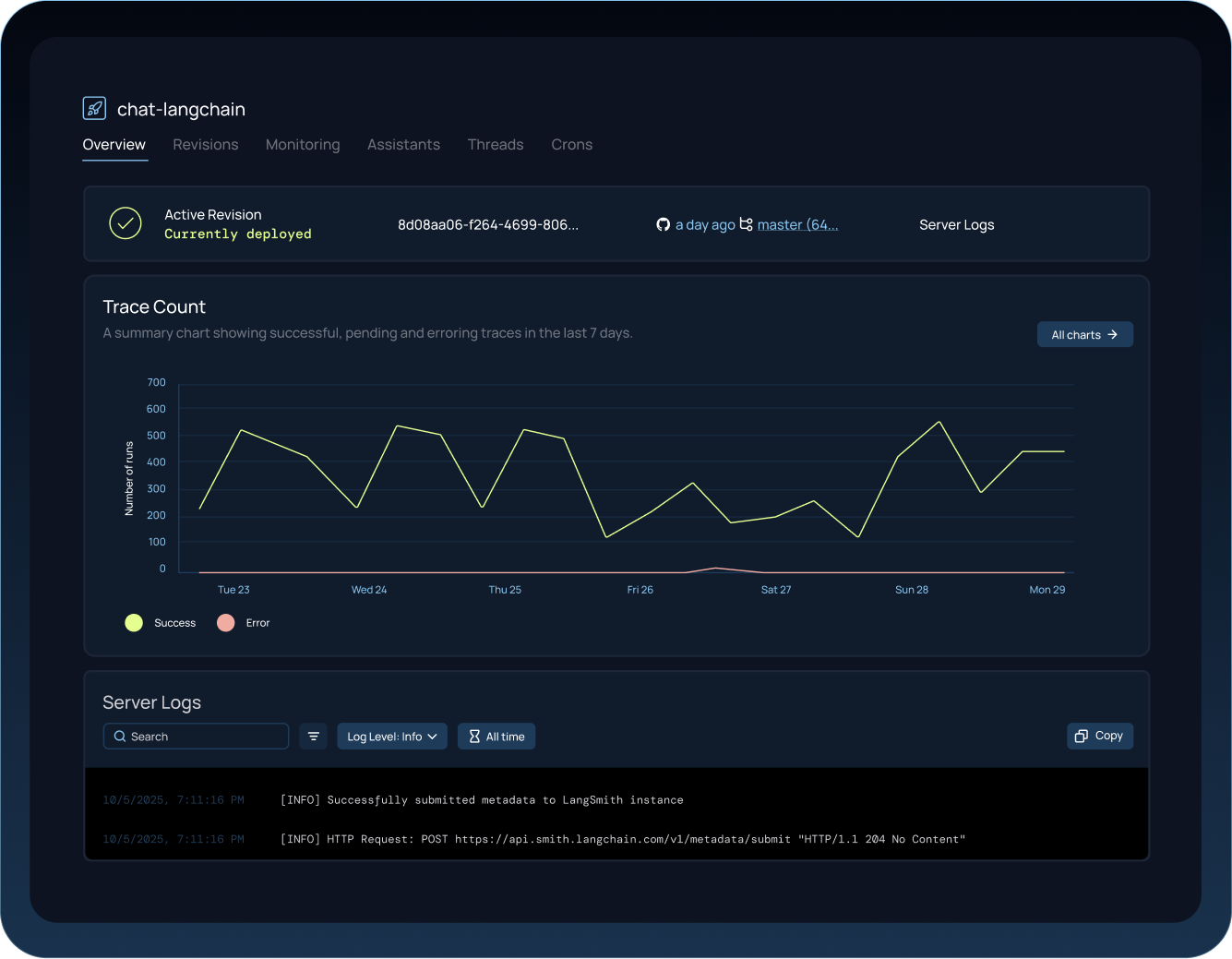
Managed deployment for stateful AI agents
Braintrust's deploy functionality covers prompt versioning and environment management. But Braintrust doesn’t offer deployment of agents themselves and has no container orchestration or long-running process support.
We built LangSmith Deployment as a managed runtime purpose-built for stateful LangGraph agents. It handles durable execution, task queues, persistence, and 1-click GitHub deploys.
- Long-running agent support: AI agents that run for minutes or hours stay alive with automatic state checkpointing.
- Human-in-the-loop patterns: Agents pause for human approval, then resume exactly where they stopped.
- Horizontal scaling: Bursty workloads scale automatically without custom infrastructure.
LangSmith Assistants let you inject runtime configuration into agents and prompts, so you can run A/B tests without redeploying code. Braintrust prompts are static code objects, so you cannot update or parameterize them, and they cannot affect code-level configuration at runtime. Each change requires a code push.
Governed human review on every plan
Braintrust limits review scorer configuration to one scorer per project on the Starter plan. Unlimited scorers require Pro or Enterprise. Its human review docs show no approval workflows or consensus mechanisms
LangSmith annotation queues have structured review workflows where engineers, PMs, clinicians, and analysts contribute scores. We include approval gates on the free plan. Assignment routing comes standard.
- Structured scoring: Define custom rubrics that match your domain requirements.
- Assignment routing: Send specific traces to the right reviewer automatically.
Podium's team used LangSmith's evaluation workflows to reach a 98.6% F1 score on their AI agent. They reduced engineering intervention by 90% through systematic evals and dataset curation powered by production traces.
What Klarna built with LangSmith
Klarna deployed a multi-agent system using LangSmith for step-by-step trace visibility and test-driven development. The result: reduced resolution times by 80% and achieved a 70% automation rate across customer service workflows.
That scale of production AI agent deployment requires more than evaluation tooling. It requires tracing to understand behavior. It requires evals to measure quality.
35% of the Fortune 500, including companies like Workday, Cloudflare, Morningstar, and ServiceNow, trust LangSmith across the full agent lifecycle, from Studio-based development to production observability and continuous improvement.
Switching from Braintrust to LangSmith
You already have datasets and scoring logic. The transition preserves that work:
Datasets transfer directly: Export your Braintrust datasets and import them into LangSmith's dataset format.
Scoring logic maps to LangSmith evals: Your existing scorer functions translate to LangSmith evaluators with minimal refactoring.
Tracing instruments in minutes: Add the traceable wrapper to your existing code with no framework migration.
Most teams trace in production within a day. Full evals migration takes one to two weeks based on scorer complexity.Our support team helps with migration planning and scorer translation during onboarding.
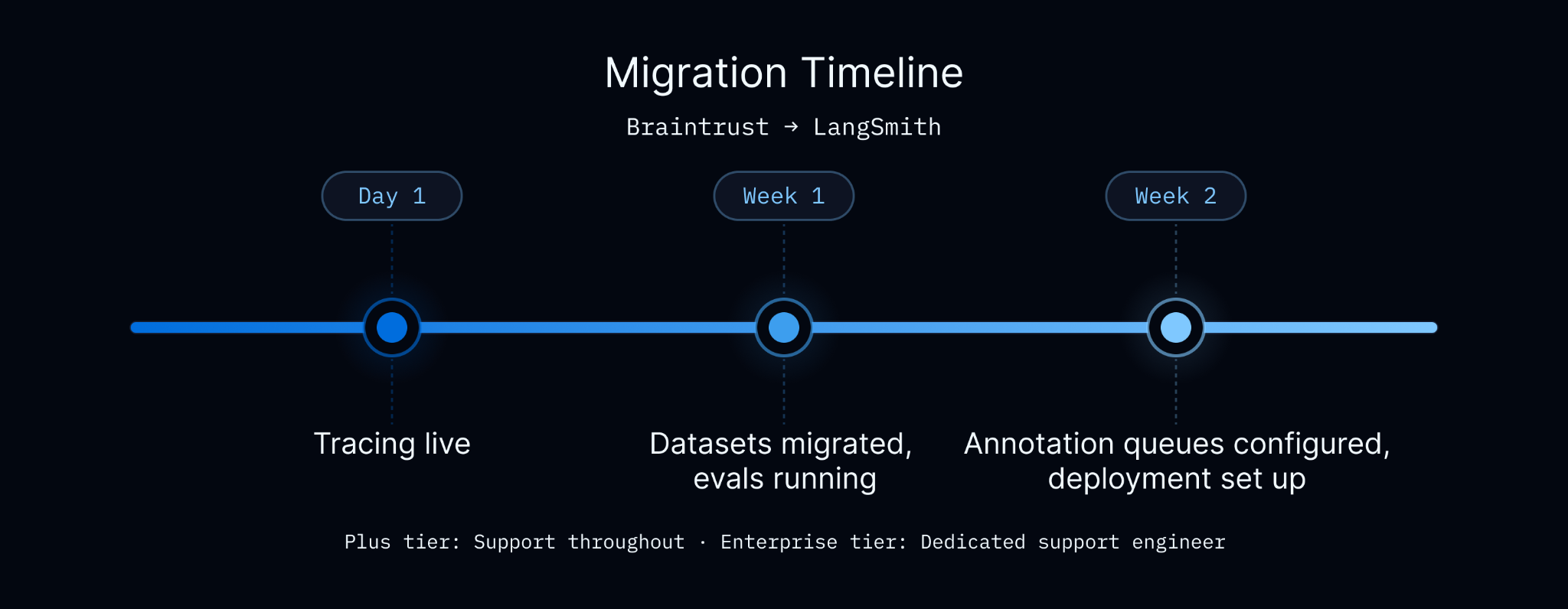
When to use LangSmith vs Braintrust
Use cases where LangSmith excels
Understanding agent behavior at scale
Insights automatically analyzes production traces to surface usage patterns, common behaviors, and failure modes. Know what users are asking, where your agent fails, and what to prioritize next.
Complex agents
When your agents use loops, sub-agents, and tool calls, LangSmith's graph-based Studio lets you visually step through execution, fork at any point, and isolate issues at the sub-component level.
Multi-turn chat & assistants
LangSmith organizes messages into threads, then evaluates the full conversation rather than isolated calls. This matters for chatbots, copilots, and support agents because quality depends on context across turns.
Enterprise AI agent programs with governance requirements
Annotation Queues route outputs to domain experts with structured scoring rubrics. PMs contribute their perspective. You can audit every trace from input through final output. Teams standardize evaluation practices across dozens of AI agent projects.
Iterative AI agent quality improvement
With LangSmith Engine, your production traces are clustered into prioritized issues automatically. Engine suggests a PR for a fix, and creates your offline evals automatically so the regression doesn’t happen again. Engine turns production failures into regression tests automatically.
Move to metric-driven agent engineering
LangSmith gives you the full lifecycle: trace, evaluate, deploy, and improve your AI agents in one framework-agnostic platform.
Get a demo of LangSmith's agent engineering platform
Frequently asked questions
How long does it take to switch from Braintrust to LangSmith?
Most teams have production tracing running within a day using the traceable wrapper. Full migration of datasets and evals takes one to two weeks.
Will I lose data when migrating?
No. You export datasets from Braintrust and import them into LangSmith. Your scoring logic maps to LangSmith evaluator functions with minimal changes.
How does LangSmith pricing compare to Braintrust?
LangSmith starts at $0/seat/month on the Developer plan for 1 user seat with 5,000 traces per month included. Braintrust's Starter plan has no platform fee and includes 1 GB of processed data per month with 14-day retention. On-demand usage pricing applies beyond those included limits on both platforms.
Does LangSmith require the LangChain framework?
LangSmith is framework agnostic. It works with the Deep Agents, LangChain, and LangGraph, plus any other stack. You instrument with the traceable wrapper regardless of your orchestration choice.
Can LangSmith handle long-running AI agent deployments?
Yes. LangSmith Deployment provides managed infrastructure for stateful LangGraph agents that run for hours or days. Because LangSmith is framework-agnostic for tracing and evals, you can observe any agent. When you're ready for managed deployment, LangGraph gives you the runtime.
We built in durable execution and task queues with human-in-the-loop pause/resume patterns.
Does LangSmith support both offline and online evals?
LangSmith supports offline evals against curated datasets. It also supports online evals on live production traffic. Both feed into the data flywheel: traces become datasets that power evals, closing the loop on quality.
Can LangSmith help me turn production failures into test cases?
Production Automations route traces to datasets and annotation queues automatically based on rules you define. There’s no manual triage. Insights Agent then categorizes those failures into usage patterns and failure modes so your team can prioritize fixes. Braintrust supports webhooks and exports but has no native trace-to-dataset or trace-to-queue automation, so this work is manual.
Does LangSmith support multi-turn conversation evaluation?
Yes. LangSmith provides a native thread view that groups multi-turn conversations into a single trace, plus thread-level evals that score quality across the entire interaction. Braintrust's thread view is a linearized span log without conversational semantics, and it can't group messages into a session for evaluation.