

.png)
Key Takeaways
- Verifiers can be a cost bottleneck for running agent evaluations and RL post-training at scale.
- We find we can reduce verifier costs by an order of magnitude by batching verifiers and using open models.
- Tuning prompts for verifiers allow us to target particular behavior further.
Authors: Vivek Trivedy (LangChain), Jake Broekhuizen (LangChain), Harrison Chase (LangChain), Niko Grupen (Harvey), Gabe Pereyra (Harvey), Spencer Poff (Harvey), Julio Pereyra (Harvey)
Earlier this month, Harvey released LAB, an open-source benchmark for evaluating agents on complex legal work. The initial results show that legal work is far from saturated with today’s agents.
Together with Harvey, we tackled the following question:
How can we more efficiently verify the correctness of a legal agent’s work?
Why does this matter? Legal work is a particularly difficult domain for agents because it spans many documents that fill context, requires specialized knowledge, and has strict criteria that need to be followed for an output to be acceptable.
The LAB benchmark approaches verification much like a human reviewer would. Every task in the dataset has a set of criteria that must pass for the task to pass. Every criterion is evaluated by an individual LLM judge using a verifier model. For each criterion, the verifier gets the agent output and the match_criteria it needs to measure. It outputs a verdict per criterion. Many tasks have over 50 individual criteria to verify. Making an LLM API call for each of those criteria gets expensive at scale with frontier models.

Can We Run More Efficient Verification?
The cost of running frontier verifiers creates a practical question for teams running legal-agent evaluation or training legal agents with RL:
How can you best reduce the cost of verifiers while remaining close to frontier performance?
We study two different methods of doing more efficient verification:
- Use fewer tokens
- Use cheaper tokens
First method we explore: using fewer tokens. In order to use fewer tokens, we propose running verifiers in batch. That is - rather than using an LLM call for each criterion independently, we can ask it to judge the full rubric in a single batch call.
- Per-criterion scoring: run one judge call for each rubric requirement.
- Batch scoring: run one judge call for the task and ask the judge to label every rubric requirement at once.
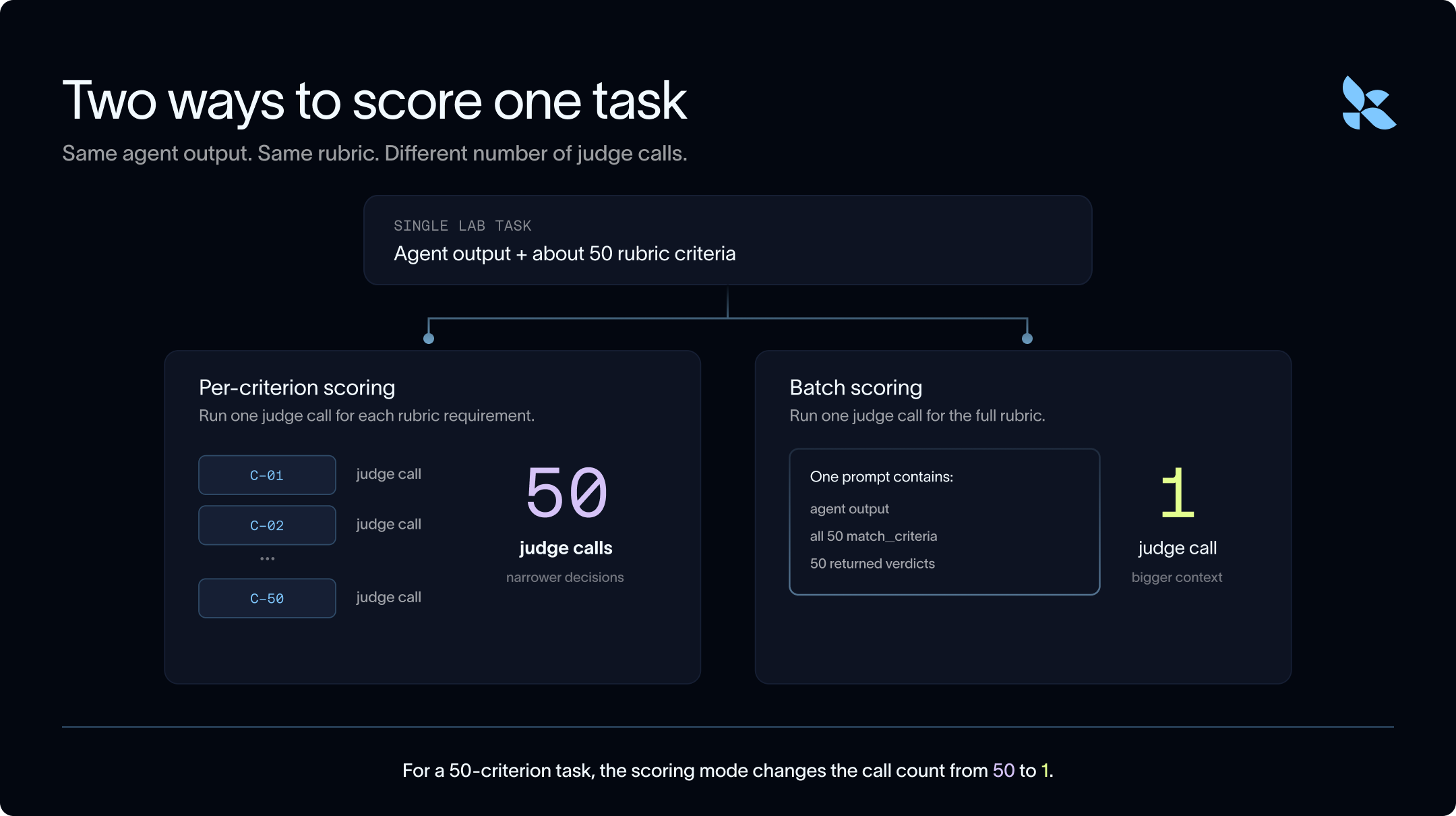
Second method we explore: using cheaper tokens. To use cheaper tokens we can test cheaper models during verification. We used Opus 4.7 per-criterion as the reference and compared GPT-5.5, Sonnet 4.6, DeepSeek v4 Flash, and Claude Haiku 4.5 across per-criterion and batch scoring.
Experiments to Measure Efficiency across Verifier Designs
To run our verifier experiments, we first needed to produce a set of outputs for the verifier to evaluate. To create these outputs, we ran an agent (powered by Kimi K2.6) over 40 public LAB tasks across the following practice areas: Corporate M&A, Tax, Emerging Companies/VC, and Trusts and Estates.
Across these 40 tasks were 2,348 individual rubric criteria - each is scored as pass/fail by a verifier. We first run Opus-4.7 across all criteria as a baseline. This gives us a baseline to compare against when testing GPT-5.5, Sonnet 4.6, Haiku 4.5, and DeepSeek-V4-Flash as other verifier options. Every verifier run will produce the same 2,348 criteria scores (pass/fail) and we can use these to study how they compare.
For each verifier run, we measured:
- Agreement: how often it matched Opus per-criterion labels.
- False pass: how often it passed a criterion that Opus failed.
- False fail: how often it failed a criterion that Opus passed.
- Cost: observed token cost for the 40-task verifier run.
We paid particular attention to false passes. In real world settings, a failed criterion can be escalated for further review. That is usually preferable to letting a criterion pass when it should fail in a domain like legal.
Verification, like most agent-system design, is a tradeoff between performance, cost, and time. Per-criterion verification gives the judge a narrower decision window, but it requires many more calls. Batch verification is cheaper and faster, but the judge has to track the full rubric at once.
The chart below shows cost versus label drift. The x-axis is verifier cost per 1,000 rubric criteria. The y-axis is disagreement with Opus per-criterion labels, or 100% - agreement. Lower and further left is better.
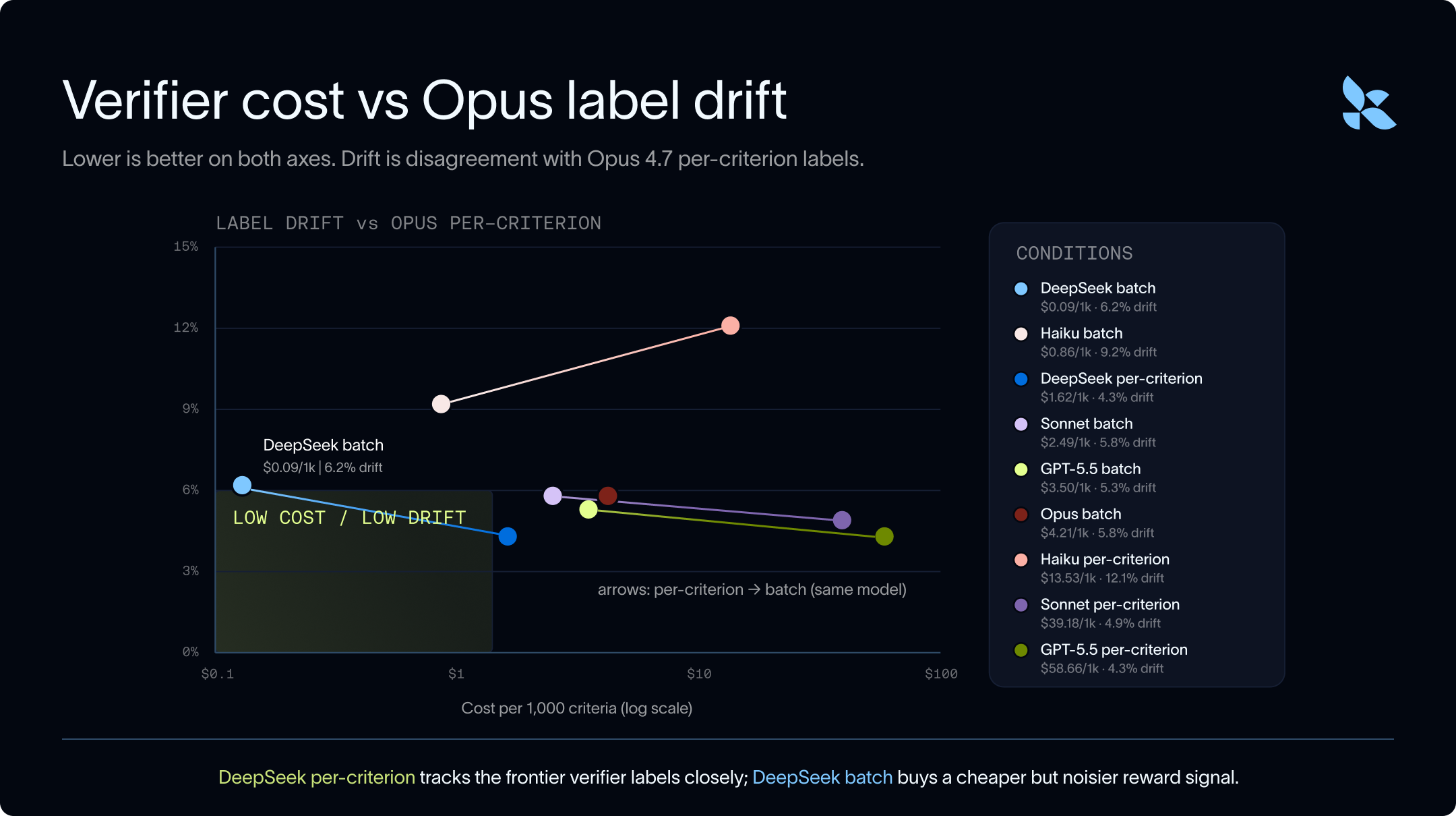
Some takeaways:
- Across the board, running in batch mode has lower match rates than running in per-criterion mode. But running batch is an order of magnitude cheaper to run for the same model as it saves on repeated input token costs.
- Even frontier models like GPT-5.5 and Opus disagree on labels - they only have a 95.7% match rate. This means that some of the datapoints may not be sufficiently specified for models to apply them as consistently as experts. This also means that targeting 100% match rate may not be realistic, and a match rate of 95.7% may be a reasonable upper bound.
- DeepSeek is a strong approximation of Opus as a verifier, both running one criterion at a time and running in batch mode. It can also be run 3 orders of magnitude more cheaply which makes it a good candidate for large data and training domains where you need to run verification at scale.
- Haiku was cheaper than Opus and Sonnet, but much more permissive. Its false-pass rates were 48.4% per-criterion and 34.7% batch, which is the wrong failure mode for legal verification.
Cost savings on post-training
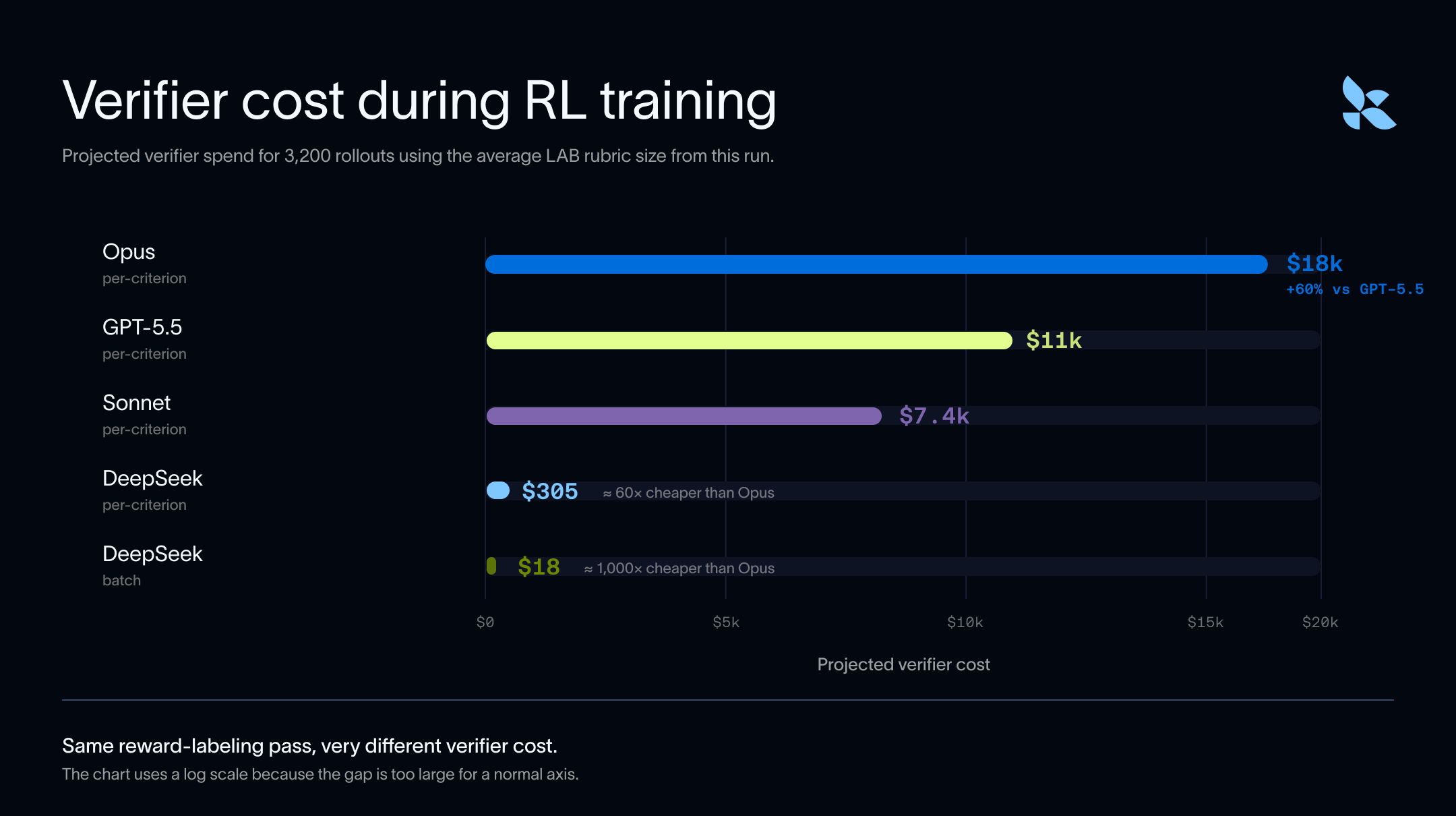
Verifiers are not just used for evals. They are also used for post-training, and verification costs are amplified here, due to the multiple rollouts per task. LLM-as-judge systems turn task rubrics into reward signals, and cheaper reward signals make it practical to run more experiments, audit more rollouts, and iterate faster.
A quick pass at extrapolating costs show that DeepSeek can be run 60-1000x cheaper than frontier verifiers at scale. This becomes especially important in domains that are not easily programmatically verifiable and require some amount of LLM as a Judge to produce a reward signal.
Tuning Verifier Behavior from Traces
The results keep the prompt fixed per model and per verifier architecture (per-criterion vs batch). One additional lever we tested was targeted prompt tuning.
In order to test the effects of prompt tuning, we ran an auto-research loop on the previous results of DeepSeek compared to Opus. We looked at why & how DeepSeek diverged and tweaked the prompt over several runs. We told it optimize for false-pass rate.
One key reason for some of the DeepSeek errors with the default prompt was that DeepSeek was too willing to pass criteria when the answer was related to the requirement but did not satisfy every material part. The final prompt made the verifier decompose each piece of each criterion more explicitly as a checklist and instructed it to be cautious if the information present wasn’t totally clear. This reduced DeepSeek false-pass rates in both scoring modes: from 10.7% to 9.5% per-criterion and from 15.6% to 14.2% in batch.
Mining traces for data and doing targeted distillation of behavior via prompting continues to be an effective strategy for improving verifiers and agents in general.
Building Better Agents & More Efficient Verification Systems for the Legal Domain
Verifiers are one piece of the puzzle for building world class legal agents. Open model verifiers give us a cost-performance tradeoff that allows teams to run evals and do RL post-training orders of magnitude more cheaply, and often makes it feasible to attempt in the first place. We also find that simple methods like batching verification work reasonably well and provide another order of magnitude reduction in cost.
Open models also give firms the opportunity to fine-tune bespoke verifiers for their most crucial domains. A lot of work assumes that frontier closed models are the gold standard to distill towards, but even Opus, GPT-5.5, and Sonnet disagree on roughly 4-5% of labels in this study. We feel there’s more work to be done to challenge this belief further.
We’re excited to partner with Harvey to push forward research on better verification systems at scale. In future work, we’re excited to study the impact of fine-tuning verifiers and their impact on post-training and running evals at scale.


