


Guest post by Ben Levine and Patrick Hendershott, Candidly
From Ex-Post Evaluations to Live Steering
Most conversational assistants are judged after the fact, by how the conversation ended. Did the user get an answer? Did they complete the task? Did they return, click through, or take the next step?
Those labels define the objective, but they're observed only at the end, while the assistant acts turn by turn. To optimize for resolution during the conversation, the agent harness needs a turn-level view of where the interaction is and which response levers can move it forward. We build that view by reading the partial trace, inferring the user’s current state, and selecting response features based on how similar conversations shifted in the past.
Candidly helps people make high-stakes financial decisions around debt payoff, savings, retirement, benefits, and education costs. Cait is our AI financial planner—a conversation agent that helps compare savings strategies, repayment options, understand deadlines, evaluate tradeoffs, and decide what to do next. For example:
- “How do I balance saving for the future with paying off my debt?”
- “How can I create more space in my budget? Can I afford college for my child without sacrificing retirement?”
- “Should I pause my 401(k) contributions to pay off my student loans faster?”
This post builds on a formal research paper and a multi-month analysis of production Cait conversations. The goal was not to produce a research artifact in isolation, but to turn conversation analytics into a policy surface Cait’s harness could actually implement. Our first question was retrospective: after a Cait conversation ended, could we tell whether it had resolved the user question or been abandoned?
Can We Predict How a Conversation Will End?
To assess conversation-level outcomes at scale, we built a hybrid labeling pipeline over production Cait traces and tracked the resulting labels in LangSmith. Deterministic rules handled clear cases like explicit frustration, no reply after Cait's first message, or product follow-through such as linking an account or starting a savings plan.
Ambiguous cases went to LLM-as-judge evaluators, routed by conversation pattern. Each verdict attaches to its thread as feedback. We calibrated the pipeline against a human-labeled LangSmith dataset, reaching 92.3% agreement.
Then we trained a model to predict that label from features computed directly off the trace. A few examples of these features, split between what Cait did and how the user responded:
What Cait did
- Q/A alignment: the lexical overlap between Cait's response and the user prompt that preceded it. High alignment is one of the strongest predictors of resolution in our data; and low alignment is a defining signature of the failing state.
- Topic continuity: the semantic persistence of Cait’s own responses. For Cait response at turn t, it measures the semantic similarity between Cait’s current response aₜ and Cait’s previous response aₜ₋₁. Continuity and coherence across the trajectory strongly predicts resolution.
How the user responded
- Message length: Longer messages predict resolution; low or one-word replies predict a user on the way out.
- Caps ratio: the share of the user message in capital letters (a frustration signal that predicts abandonment).
All of our features are lightweight and deterministic at runtime, with a few string and embedding operations per turn, computed in milliseconds.
A gradient-boosted model trained on these features separated resolved from abandoned conversations apart at 0.90 AUC (0.5 is chance, 1.0 is perfect). Resolution versus abandonment was predictable from signals in the traces.
The next step was to represent those signals in a form Cait could use before the conversation ended: turn-level state inference paired with the controllable response features that can shift it, updated on every turn. The rest of this post describes how we built that loop into Cait's agent harness, from traces to states, states to policies, and policies to experiments.
Turning Traces into a State Model
We care about modeling the complex interaction between the user, the agent, and the conversation context. The prediction results told us that conversation outcomes are learnable from the trace. To make that signal useful while Cait is still talking to the user, we need a model of how conversations unfold, including: how the observable signals accumulate over turns, which patterns tend to recur, and which parts of Cait’s behavior are associated with movement toward or away from resolution. We compute these features from the trace, deterministically and in milliseconds, then keep them in LangSmith alongside the user message, Cait's response, inferred state, and, upon completion, the conversation outcome.
A useful model has to do three things:
- Represent the conversation as an ordered trajectory we can interpret and act on.
- Separate user-side signals from agent-side features, because they play different roles. User behavior tells us what state the conversation is in, while agent behavior is the lever the system can move.
- Learn the mapping from signals to states from the data itself, so the states reflect the patterns that actually appear, rather than categories we impose in advance.
A model with those properties gives us more than a retrospective score. It can read the partial trace, summarize where the conversation appears to be, and connect that readout to response features Cait controls. That is what makes the model operational; it produces something the agent can use before the outcome is realized.
An Input-Output Hidden Markov Model meets all three requirements. Heavier alternatives like an RNN or trace transformer trade away interpretability and a clear real-time intervention path.
Inside the IO-HMM
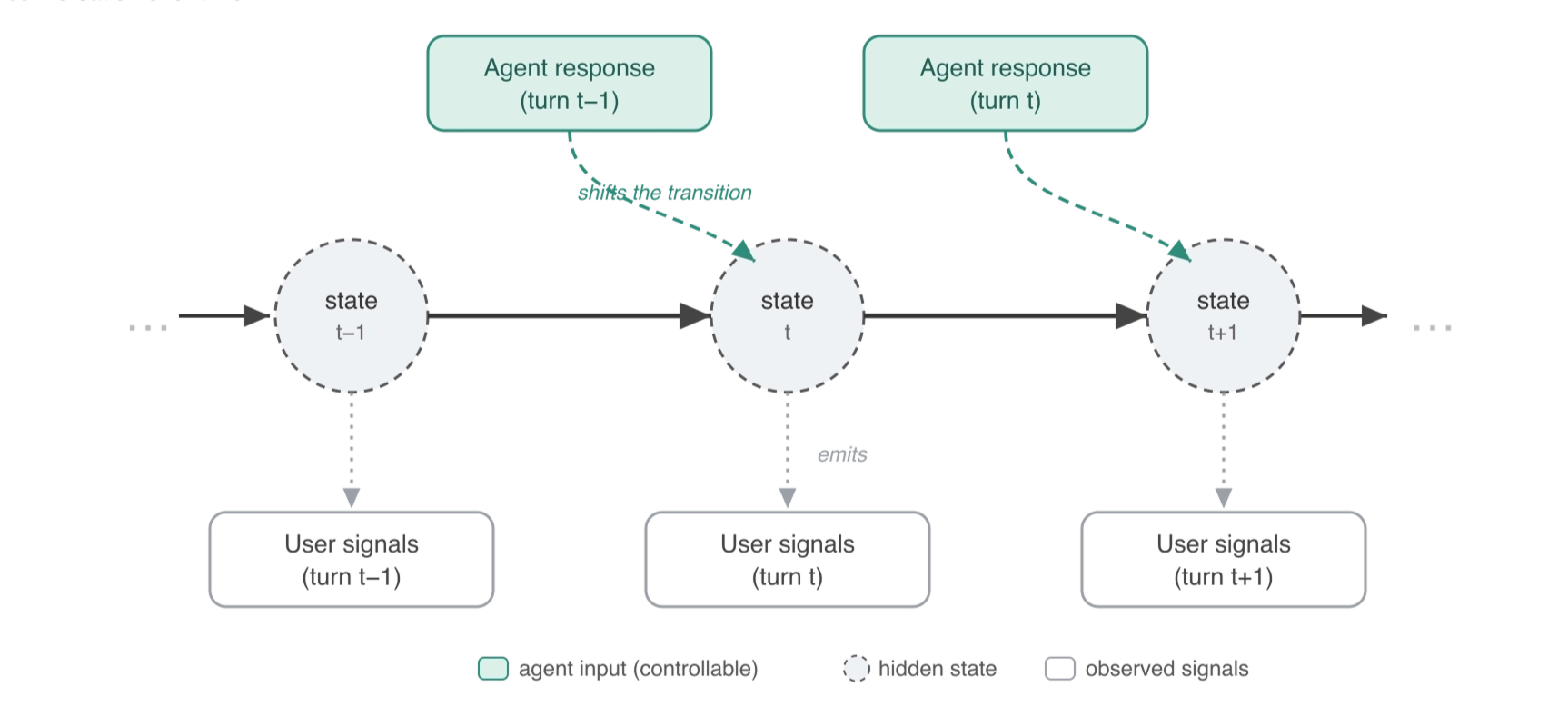
The IO-HMM separates each turn into two pieces:
- User-side signals are emissions. They are the observable behaviors we use to infer the user's current engagement state.
- Agent-side features are transition inputs. They are the controllable response characteristics that condition where the conversation moves next.
The model estimates where the conversation is likely to move next, given where it is now and how the agent just responded.
The model is fit across thousands of conversations using expectation-maximization. Fitting learns two things at once. 1.) the engagement states themselves (recurring patterns in user behavior across conversations)and 2.) the transition function (how agent-side features associate with movement between states). We settled on four states for the best held-out fit, BIC, and stable interpretability.
Smaller models collapsed distinct engagement patterns, while a five-state model did not recover a consistent, usable regime.
The important design choice is the separation. User behavior is used to read the state of the conversation. Agent behavior is used to estimate transitions between states. That separation turns traces from a record of what happened into a model of what is driving the conversation.
Four Engagement States, and Why Averages Hide Them
The model recovered four interpretable engagement states:
The states differ in both behavior and outcomes. They map to whether users get their question resolved, continue exploring products, or abandon the conversation. Resolution ranges from about 78% in the most engaged state to about 30% in the disengaging state.
The states also respond differently to the same agent behavior. Holding topic continuity keeps an engaged user on track, but can trap a disengaging user in the lowest-resolution state. Pushing a visual artifact can move a detailed user forward, but makes recovery harder for a disengaging user. This is what a conversation-level average obscures. Pool that behavior across every conversation and its gain in one state cancels its loss in another, so the net effect is a biased estimate. Once we condition on state, the policy signal becomes visible.
That turns the model into a policy surface…a map from where a conversation is to the response change most likely to move it somewhere better. For example, adding a call to action keeps a Detailed conversation from sliding into Disengaging, and mirroring the user's function-word patterns helps a Disengaging one recover toward Engaged.
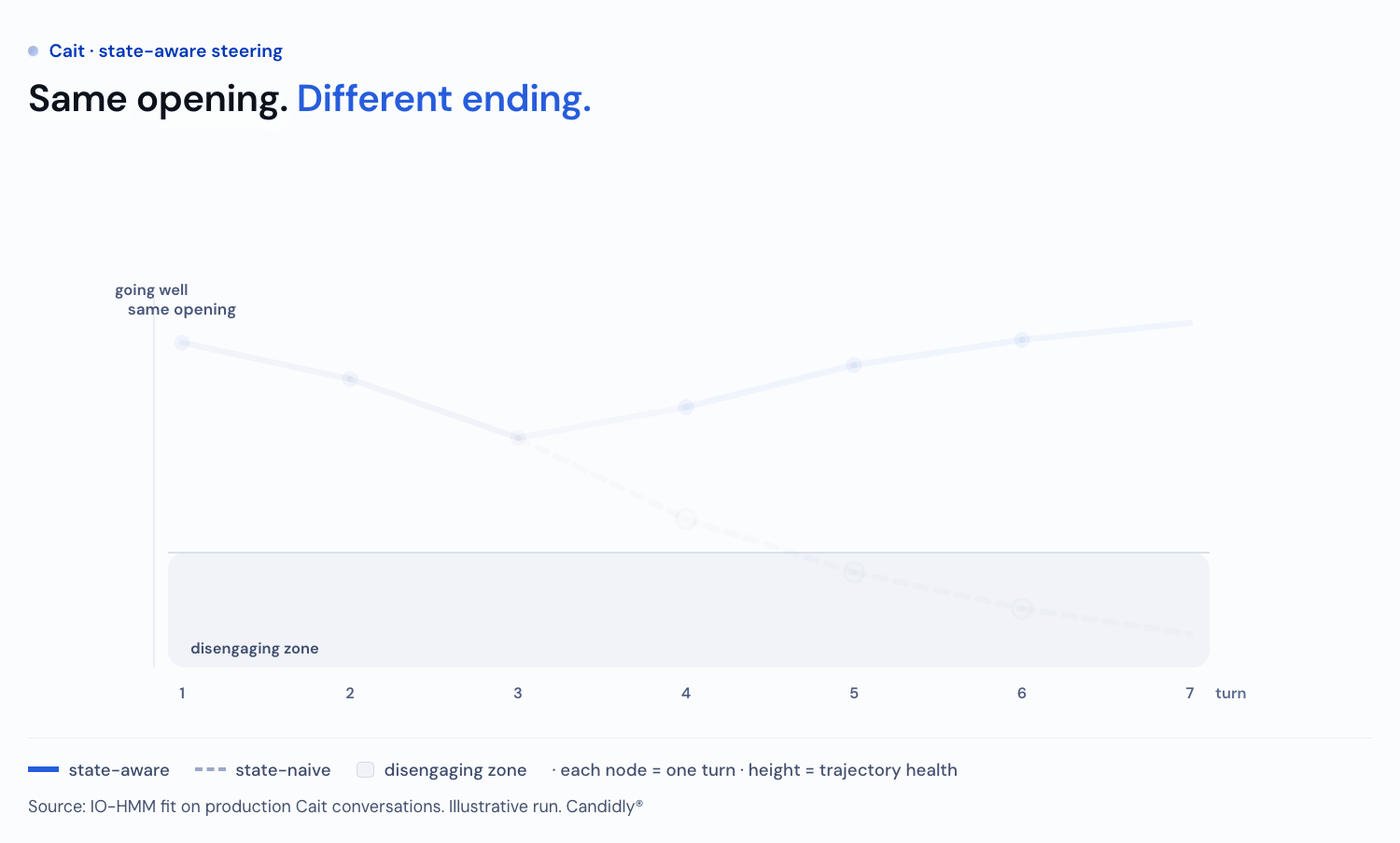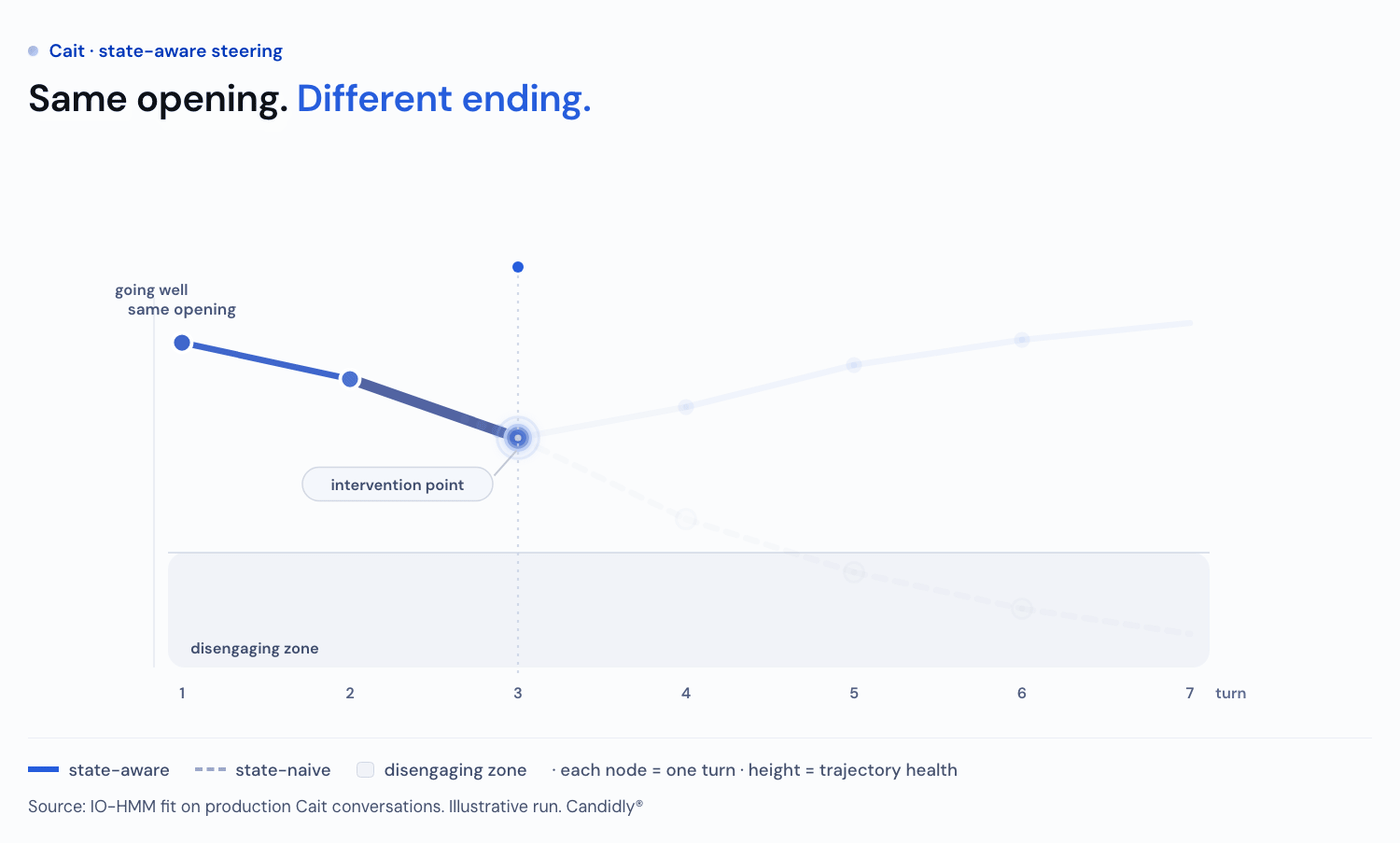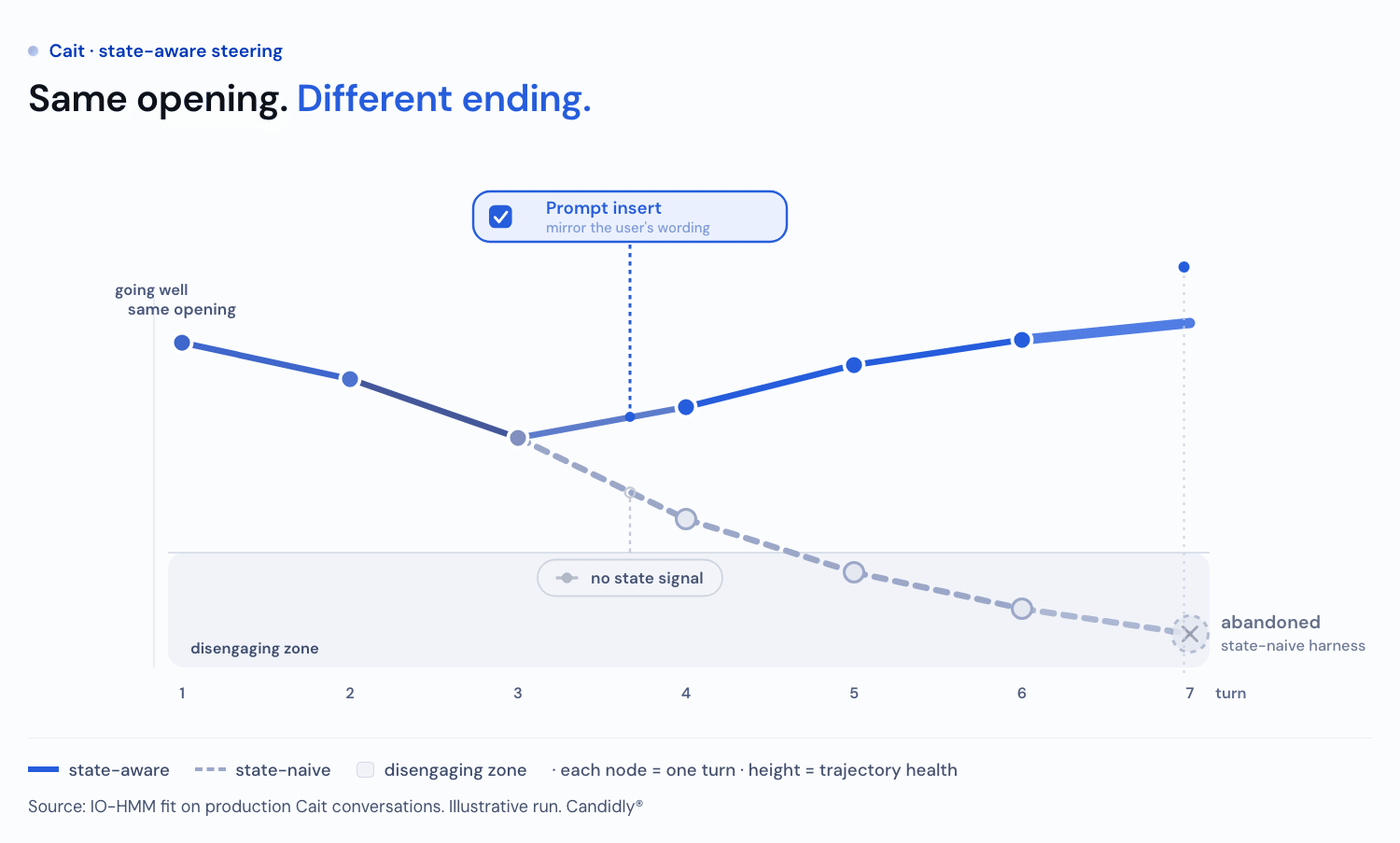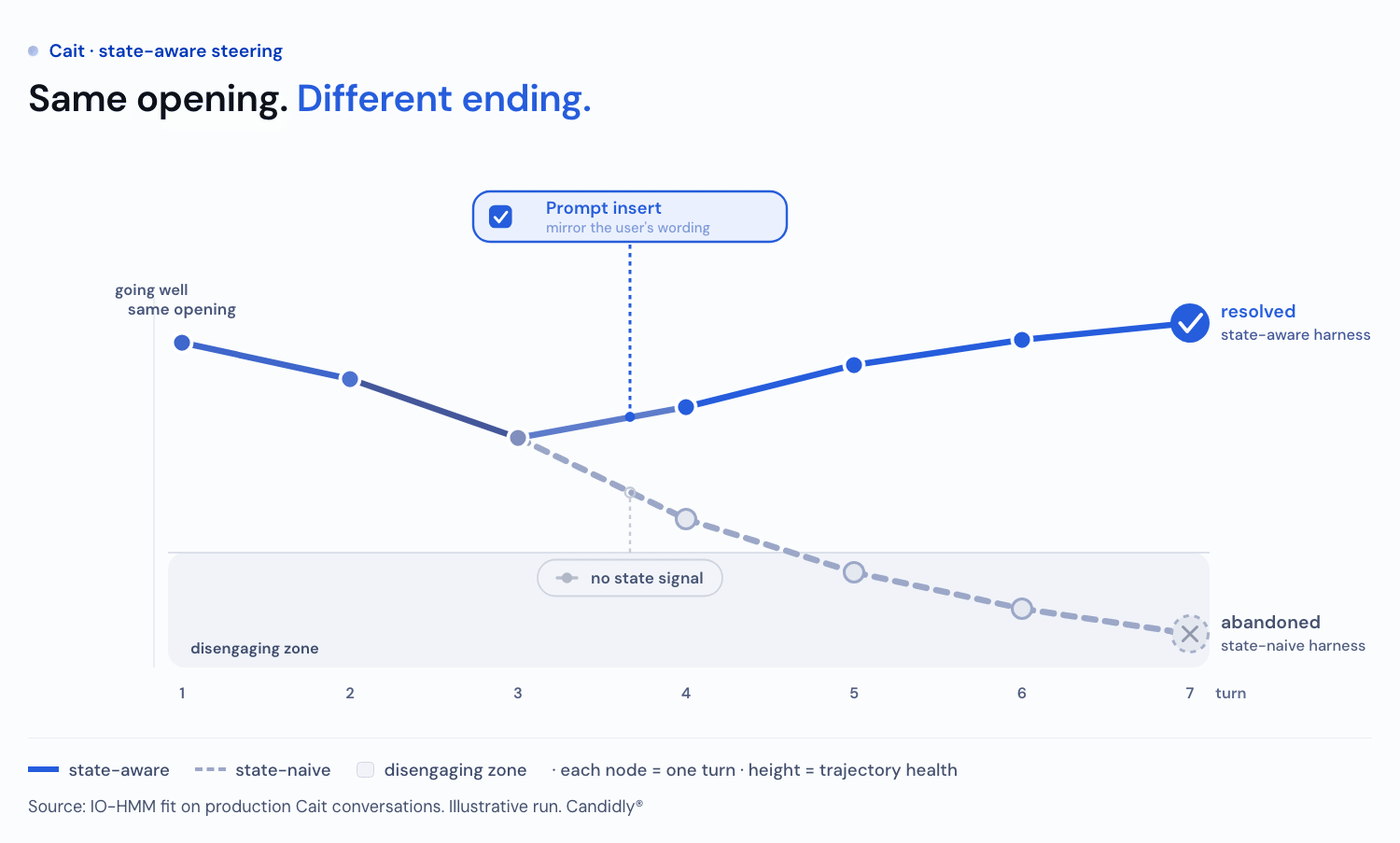
We want our proposed policy to maximize the probability of in-conversation resolution. Given how far apart the states sit on resolution, the policy follows straight from the objective: keep conversations in the high-resolution states and out of low resolution states. The model gives us the policy to do exactly that, halving the share (from 23% to 11%) of user turns in the Disengaging state and routing most of it into Engaged (53% to 64%).
Wiring the Policy into the Harness
A fitted model is not yet a policy. To act on it, the model has to run inside the harness, every change it drives has to be recorded, and its effect has to be verified before launch and measured after.
State inference in the request path. The model runs on every turn, fast enough to shape the next response. We freeze the fitted parameters, compute the user's current state from the signals already in the trace, and write that state back onto the trace as metadata, inside the latency budget of a single reply.
A versioned change per state. Something has to turn the inferred state into a different response, whether a prompt insert, a tool choice, or a different template. Each lives as a versioned policy regime in LangSmith, and the version that fired is recorded on the turn, so we always know which change was applied.
Offline verification. Each state-aware policy change dynamically appends to Cait’s prompt directives to nudge the user into a better state. Before shipping, we replay it on a held-out LangSmith dataset, regenerate Cait's response under the new prompt, and score it with our evaluators to confirm it produces the intended shift, without disturbing the rest of the response. Only prompts that pass become an experiment arm.
Randomized assignment. Cait’s responses are not assigned at random. They already depend on the user’s message and the conversation so far, so the model can learn which states call for which responses, rather than whether a response changes the trajectory. A randomized experiment supplies the missing exogenous variation. Each user is assigned to the existing behavior or the state-aware policy, with assignment held stable and tagged on every trace. LangSmith lets us monitor the two arms as they run, so we can watch state occupancy and resolution diverge before the full outcome read is in.
One record for the whole loop. The inferred state, prompt version, experiment arm, outcome, resolution, and product activation all sit on the same trace.
LangSmith closes the loop; traces become state-aware eval data, eval data becomes prompt-policy experiments, and production monitoring tells us whether the policy changed the trajectory.
Building Better Agents: Evaluation as a Control Signal
Our model gives an agent something a post-hoc success score never can: a turn-level read on where the interaction is, available while the agent can still act on it, turning evaluation from a grade into a control signal.
Nothing about that is specific to financial conversations, or to conversations at all. The recipe requires three ingredients. 1.) an outcome that's only observed at the end, 2.) turn-level signals computable from the trace, and 3.) behaviors the agent controls. Any multi-turn agent with a goal has all three.
Consider a coding agent. Its outcome—a merged PR, a passing suite—arrives at the end, but the trace contains emissions of a latent state at every turn: tests failing in new ways after each patch versus the same way every time, edits circling the same files without shrinking the problem, review comments getting shorter and more corrective. An agent in a coding session stuck in a bad state should stop, re-plan, or ask a question rather than push another patch. Most coding agents today run the same loop either way.
An orchestrator managing sub-agents has the same three ingredients too. A worker's progress report is one signal, and a noisy one; the shape of the work says more. Do tool calls keep surfacing new information? Is the plan narrowing or expanding? An orchestrator that can read convergence can intervene early—narrow the task, swap tools, kill the run—instead of leaning on turn caps and token budgets, which might stop a run one step from finishing or let a doomed one burn its whole allocation.
There is a lesson here for evals themselves. In our data, the same agent behavior could help in one state and hurt in another. Pooled, those effects canceled and the signal vanished. If we only measure whether a behavior works “on average,” we miss the more useful question: when does it help, and when does it hurt?
The longer the horizons agents take on, the wider the gap between their action and the realized outcome—and the more the agent needs something it can read in between. State is the layer that connects those two views with more precision. The final outcome defines what we want, while the turn-level state estimate gives the agent something it can use before the outcome is realized. With that state estimate on every turn of every trace, evaluation becomes part of the operating loop: the trace records what happened, the model reads where the interaction is, the policy chooses the response, and the next trace shows whether that choice moved the conversation in the right direction.
About Candidly
Candidly is the category leading, AI-native technology platform delivering holistic financial guidance to employees through employers, financial institutions, and workplace service providers. Founded in 2016, the company’s mission is to help hardworking Americans move beyond debt, into wellness and ultimately wealth through comprehensive, holistic, and personalized digital experiences. Through these partnerships, Candidly is positioned to serve 1 in 2 U.S. workers.
About the authors
Patrick Hendershott is a Senior Data Scientist at Candidly, where he builds statistical and machine learning models to understand user behavior and improve AI product performance. He focuses on applying measurement, experimentation, and modeling to AI engineering, helping Cait learn from real user interactions and turn those insights into better conversational systems.
Ben Levine is Chief Product Officer at Candidly and the architect behind Cait, the company's AI financial planner. His work combines product leadership with deep technical fluency in machine learning, experimentation, and econometrics. He builds at the seam where product meets the math, and is most interested in turning hard modeling problems into agents that move users toward better financial outcomes.
