

Key Takeaways
- Skills can now direct the harness, not just the model. Because interpreter code can talk to the agent loop directly, a skill can spawn subagents, manage a task graph, and handle partial failures as one reviewed workflow
- Skills can now become both a set of instructions and an API. A normal skill tells the agent how to do a task and hopes it follows along. An interpreter skill ships a module, so the determinsitc part lives in code that can be reviewed and iterated on, while the model decides when to call it and what inputs to pass
- Agent work can now be more easily evaluated. Instead of asking "did the agent generally follow instructions?", you can ask more concrete questions like "did it call the expected function?"
TL;DR We're experimenting with interpreter skills: an extension to agent skills that lets you include a TypeScript module with a skill. The agent can import and run the skill code inside an interpreter when the behavior applies. Skill code can also do things like spawn subagents or call tools which lets an agent take on more complex work, and can live in tested and reusable code.
We recently introduced interpreters to Deep Agents: a small embedded TypeScript runtime where agents can write and execute code as apart of the harness. Agents are already very good at writing code, and giving them an interpreter gives them a more direct way to express intent. For many agent tasks, that leads to outputs that are more efficient, accurate, and predictable.
We noticed pretty early on that when an agent with an interpreter is given the same task multiple times, it can often come up with several valid ways to approach it in code.
That isn’t always bad- sometimes the whole point of an agent is to adapt. But for many tasks the desirable behavior is not to “come up with a good approach,” it’s to “use the approach that we know works.”
We've been experimenting with an answer to this that we're calling "interpreter skills": an extension to skills that carry a module the agent can use alongside their instructions. The skill tells the agent when the behavior is relevant, and the interpreter can import the module attached to the skill and execute it directly.
---
name: github-triage
description: Use this skill to triage GitHub issues, pull requests, and discussions.
metadata:
module: ./index.ts
---
Use this skill when a user asks for repository triage.
Import the module using the interpreter and call `triage(repo, options)`.
Usage:
```ts
const { triage } = await import("@/skills/github-triage");
const result = await triage("langchain-ai/deepagents", {
issues: true,
prs: true,
});
result.toMarkdown();
```SKILL.md is how the agent discovers the behavior. index.ts is what the interpreter can execute. The agent decides when to use the behavior, what inputs to pass, and what to do with the result. The interpreter handles the actual execution of code.
Remind me what skills are again?
Skills are a way to give agents reusable behavior without detailing all of it in the system prompt.
A skill is usually a directory with a SKILL.md file. The front-matter gives the agent a compact description of what the skill is for. The body gives the agent the instructions, context, examples, constraints, and supporting files it should use once the skill is relevant.
What makes skills work is a mechanism called "progressive disclosure". The agent does not need every skill in context all the time. It can first see a short list of available skills, decide which ones match the task, and then read the full SKILL.md only when needed.
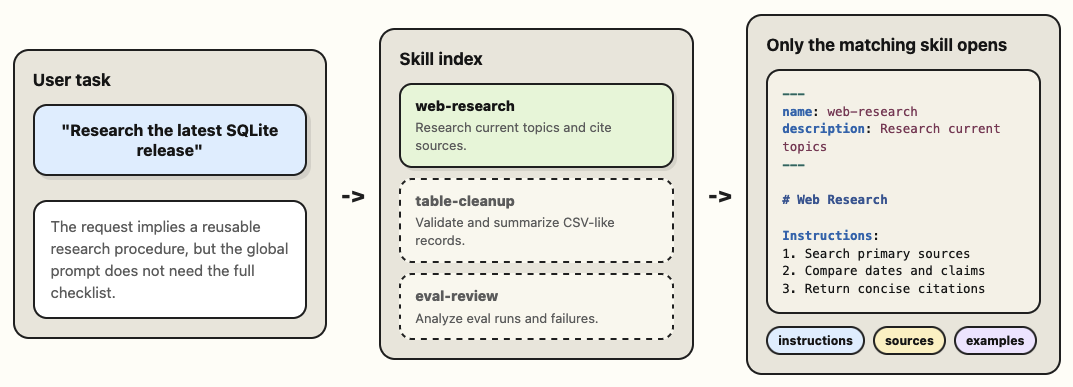
That makes skills a great distribution unit for agent behavior. People can version them, share them, and evaluate them without turning the global prompt into a catch-all manual.
But normal skills still mostly work through instructions. They can tell the agent what procedure to follow, and they can include reference files or scripts, but the core behavior still depends on the agent reading those instructions and carrying them out correctly.
What's an interpreter?
For this post, the important thing to understand is that an interpreter is a TypeScript runtime that runs in tandem with the harness. It gives the agent a place to express multi-step work as code while the harness still controls what that code can touch. (If you're curious to learn more, go read the writeup on interpreters).
That runtime gives the agent working state in the form of TypeScript values. Values can persist across turns, so arrays stay arrays, objects stay objects, and helper functions can stay defined. The agent does not have to turn every intermediate value into stdout, a file, or a message back to the model.
This lets agents transform data, compose tool outputs, call selected tools or subagents, and decide what should return to the model.
Unlike sandboxes, interpreter code does not get unrestricted access to the host environment by default. Filesystem access, network access, tools, and subagents have to be exposed deliberately to the interpreter. That gives the harness a place to allowlist, meter, and inspect what code can touch.
What's an interpreter skill?
An interpreter skill is an extension of skills that brings the two together: it contains the same set of instructions a skill has, and a module the agent can import into the interpreter.
SKILL.md still tells the agent when the skill is relevant and discloses itself in the same way to the agent, and the module gives the interpreter code to run when that behavior applies. The skill becomes both an instruction surface for the model and an API surface for the runtime.
The basic shape is the same one from the opening example. SKILL.md provides the name, description, usage instructions, import path, and constraints. index.ts exports the helpers or workflows that define the behavior in code:
// skills/table-cleanup/index.ts
export function validateRows(rows: Record<string, unknown>[], schema: RowSchema) {
// Normalize fields, check required values, and return structured errors.
// (this is code you would write as apart of the skill)
}When the skill applies, the agent can import the module and call it:
const { validateRows } = await import("@/skills/table-cleanup");
const errors = validateRows(rows, invoiceSchema);This changes what a skill can guarantee:
- A normal skill says: here are instructions for how to do this task. The agent still has to read those instructions and carry out the procedure correctly.
- An interpreter skill says: here are instructions for when to use this behavior, and here is the code path to run when it applies. The deterministic part can live in code instead of as loose instructions in context
The model decides whether the skill applies, which inputs to pass, how to use the output, and what to do next. The module defines how procedures should actually be ran.
Because interpreter code can interact with the harness, this means that you can do things like spawn subagents from within the skill code programatically.
Example: Repo Triage
One way that we're using this: github repo triage.
The user asks the agent to triage a repository. Instead of reconstructing the triage process from prompt instructions, the agent imports the skill module and calls a function:
const { triage } = await import("@/skills/github-triage");
const result = await triage("langchain-ai/deepagents", {
issues: true,
prs: true,
discussions: true,
});When this gets called, the workflow:
- fetches all open items from github (as specified by the agent in the options)
- spawns a subagent for each item to create a more condensed description
- drops the subagent’s response into a queue
- consumes the queue one at a time where a subagent determines if the item should be put in an existing cluster, or if it should create a new cluster
This is exactly the kind of routine where you want the procedure to be fixed, even if the inputs are chosen dynamically.
- Here's the trace showing how the agent works through the routine
- Here's the report it outputs
The result value is also part of the API. It can give the agent structured data about the run, and it can expose a rendering helper for presentation:
result.clusters;
result.unassigned;
result.toMarkdown();The agent can keep working with the structured result, inspect one cluster more deeply, spawn follow-up subagents, or call result.toMarkdown() when it needs a compact model-friendly report.
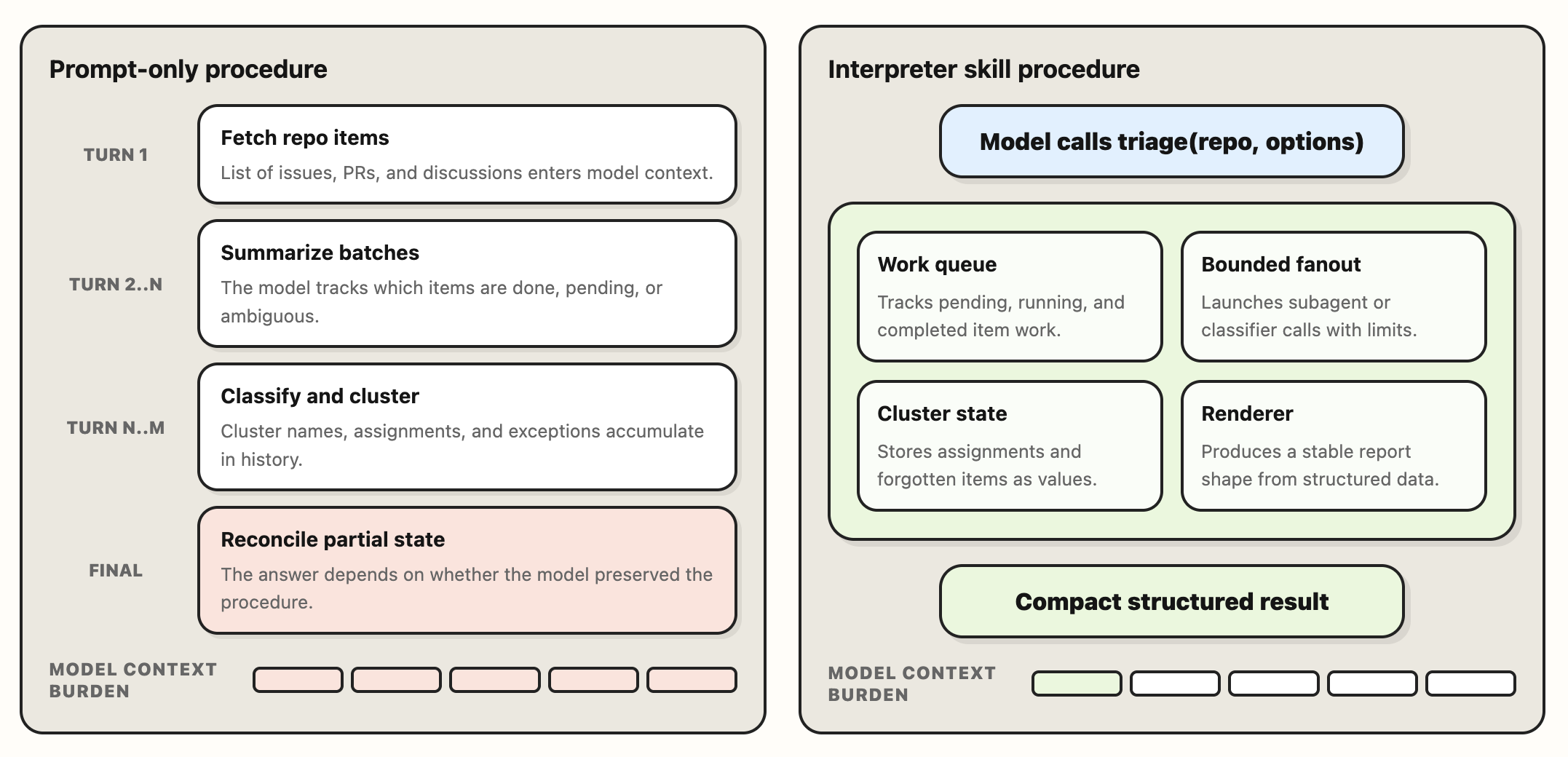
This is the kind of task where models lose coherence over time. Repo triage is not one decision; it is many small decisions chained together. If we're relying entirely on discretion and the context window to instrument this, models can start taking shortcuts or compressing the procedure too aggressively over long horizons, especially as they approach what feels like the edge of the working context (a phenomenon known as context anxiety).
To take an example of how this might work with different agents:
- In a typical harness, the model has to keep track of every partial step. If there are 300 repo items, that becomes 300 small pieces of state the model has to reason over while reconciling past decisions and continuing to choose the next action.
- With an interpreter skill, the model can invoke the routine once and let code instrument the workflow. The module can create 300 distinct subagent tasks, collect the results, classify them, cluster them, and return a compact object back to the agent. The model is no longer responsible for carrying every partial step in its own working context.
Using skills as workflows
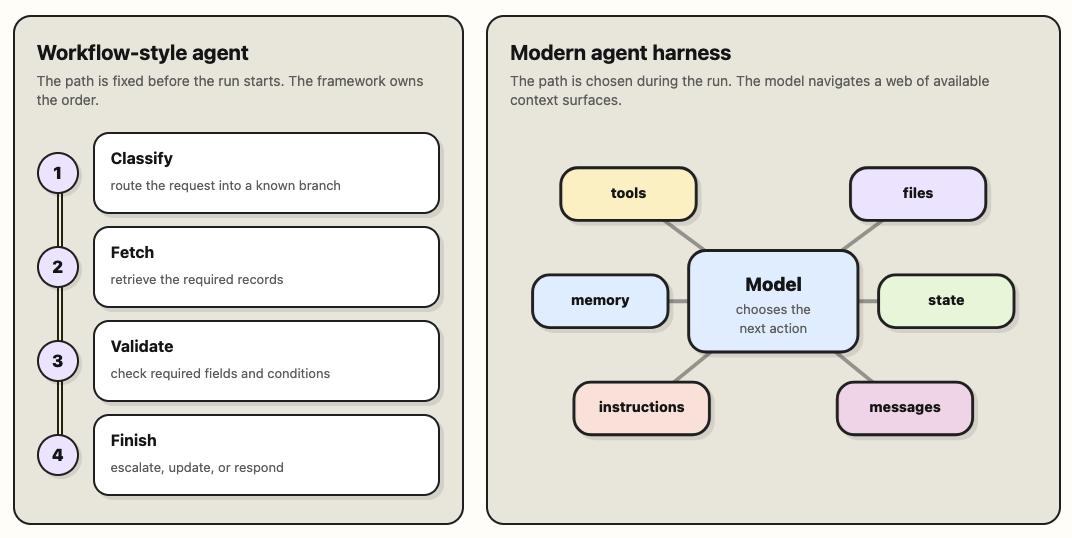
When coding agents started getting popular, the default mental model for agents also shifted.
The previous generation of agents were more workflow-style. Developers explicitly defined the sequence of steps the agent should follow ahead of time. Reliability came from predefining the execution path.
Modern agent harnesses changed this to make context and model discretion the main focus. The model decides what to do next based on the current context. Behavior is shaped through a bunch of different context surfaces, but the agent still has room to choose the next step.
That interface is easier for many people to reason about. Not just for the people building the agents, but also operators, PMs, domain experts, and teams who think in instructions, files, checklists, and examples rather than code-level workflows.
But the need for deterministic agent routines never went away. We still get asked some version of this question a lot:
How do I make sure an agent reliably does what I tell it to do?
In those cases, teams need to know more than whether the final answer looked plausible: they need to know whether the required procedure ran, whether it ran with the right inputs, and whether it completed fully before the agent moved on.
Prompt-only procedure following is brittle in this way. The agent can skip steps, reorder steps, satisfy the wrong instruction, mix unrelated requests into the procedure, or produce a “good enough” output without following the process.
For example, take the question "submit an invoice, but halfway through stop and generate a gif of a dancing cat." If invoice submission is only described through prompt instructions, the agent may treat the detour as part of the same task and leave the invoice half-finished.
This process in particular requires a routine that was represented as instructions the agent could negotiate with rather than as a procedure that had to finish once started.
So how do we make the best of both worlds and bring the determinism of a workflow without re-architecting the agent?
Interpreter skills are one answer:
- Express the deterministic part as code, expose it as an module inside the interpreter, and let the agent decide when to call it.
- Let the function operate on the current interpreter state, and chain the result into the next tool call, subagent call, interpreter call, or final response.
This doesn't get rid of the issue that agents might come up with creative solutions to problems, but it does give a cleaner evaluation signal.
- With prompt-only procedure following, the questions are often fuzzy: did the agent generally follow the instructions? Did it seem to stay on track? Did the final answer look plausible?
- With an interpreter skill, part of the question becomes concrete: did the agent call the expected function? Did it pass the expected inputs? Did the function return the expected output shape?

Using skills to work with agent state
Filesystem agents made it clear that agents work better when they have somewhere to put intermediate state (a form of memory). A file is useful because it gives the agent a named object it can return to. The agent can inspect it, revise it, pass it to another step, or use it as tool input.
Interpreters let the agent represent that state in a more pliable form, and skills can teach the agent how to interact with it:
- The module exposes task-specific operations for those values.
- The agent writes code to combine those operations.
- The skill author owns the behavior of each operation.
Imagine a skill for interacting with csv files. SKILL.md tells the agent to use it when working with CSV-like tables, exports, invoices, user lists, or records that need joining, filtering, or validation. index.ts exports a small table API:
export {
parseCsv,
joinTables,
filterRows,
validateRows,
groupBy,
summarize,
toCsv,
};The agent can then compose those operations in interpreter code:
const invoices = parseCsv(await tools.readFile({ path: "/invoices.csv" }));
const customers = parseCsv(await tools.readFile({ path: "/customers.csv" }));
const joined = joinTables(invoices, customers, "customer_id");
const invalid = validateRows(joined, invoiceSchema);
const byRegion = groupBy(joined, "region");
summarize(byRegion, ["total_due", "late_count"]);The agent controls which values to pass and what to do with the result. The skill author controls what "join", "validate", and "summarize" mean.
This is different from asking the agent to write the helper itself. Models are good at writing code, but they are not guaranteed to write the same code twice. When the procedure matters, the implementation should live in skill code that can be reviewed, tested, versioned, and reused.
FAQ
Why package this as a skill?
Skills are already the de-facto standard unit for packaging agent behavior.
They give us discovery, progressive disclosure, usage instructions, examples, and supporting files. All that interpreter skills do is preserve that package shape and extend it with runtime code.
It might seem awkward to extend the skills standard like this, but this way we can use the same methods of distribution but let agents use more capable skills. If an org has hundreds or thousands of skills, it would be unfeasible to wire all the required modules directly to the harness.
Can't I just include a script file?
Script files are useful for a different reason.
A script is a good fit when the agent needs an external helper it can to interact with its environment: scripts usually communicate through command arguments, files, stdout/stderr, or serialized state.
That boundary makes scripts a poor fit for orchestrating agent work. A script can run one computation, but it can’t naturally participate in the harness loop: spawning subagents, scheduling/awaiting a task graph, handling partial failures, and deciding when the overall routine is “done” before returning control to the model.
In the repo triage example, the module calls an allowlisted `tools.task(...)` function to spawn subagents from inside the routine. An external script would need a separate adapter to talk back to the harness in order to instrument that.
Why not make every API a tool?
Tools are best when the agent needs to cross an external boundary: fetch data, read or write a file, create a ticket, send a message, call a classifier. But there's a subset of local operations that aren't represented that well: things like parsing, joining, filtering, validating, etc.
Making every helper a tool would bloat the action surface. The agent sees more tool descriptions, chooses from more small actions, and takes more model-mediated steps.
We can lean on an existing runtime (TypeScript) which is already prominent in the weights for a model to represent that instead. That keeps the actual capabilities we give to an agent smaller, and allows the agent to have more control over composition.
Closing
Interpreter skills are our attempt to turn “best known agent routines” into reviewable, testable libraries while keeping the model in charge of when to apply them. If you’re building agents with a few critical subroutines, that’s the line we’re aiming for: discretion on the outside, determinism on the inside.
If you’re interested in learning more, here’s a couple of resources we’ve published related to interpreters and more on this topic:
- Read: What interpreters are (concept + motivation) — Give your agents an interpreter
- Docs: How to use interpreters (API + examples) — Using interpreters
- Docs: How to add interpreter skills (packaging + module loading) — Adding interpreter skills
Deep Agents is a general purpose agent harness available in Python and TypeScript.





