
.png)
Key Takeaways
- Middleware is the right place to enforce agent security. Adding security checks at the middleware layer keeps your
langchaincode clean and creates one consistent enforcement point across the agent loop, instead of bolting on logic across prompts, tools, and custom orchestration code. - Cisco AI Defense gives you two modes: monitor and enforce. Monitor mode records risk signals and decision traces without interrupting the agent. Enforce mode blocks policy violations with an auditable reason, so you can always point to exactly what was stopped and why.
- Protection applies across LLM calls, MCP tool calls, and middleware. Agents don't just generate text, they call tools, retrieve data, and take actions autonomously. Runtime protection needs to cover all three layers, especially in multi-agent systems where an orchestrator is chaining agents together at runtime.
This is a guest post by Siddhant Dash, Senior Product Manager @ Cisco AI Defense.
The problem
langchain makes it easy to move from a working prototype to a useful agent in very little time. That is exactly why it has become such a common starting point for enterprise agent development.
Agents don’t just generate text. They call skills, tools, retrieve data, and take actions autonomously. That means an agent can touch sensitive systems and real customer data within a single workflow. This compounds with multi-agent systems where an orchestrator agent is chaining many agents together and executing commands at runtime.
But visibility alone isn’t enough. In real deployments, you need clear enforcement points, places where you can apply policy consistently, block risky behavior, and keep an auditable record of what happened and why.
Why middleware is the right seam
Middleware is the clean integration point for agent security because it sits in the path of agent execution, without forcing developers to scatter checks across prompts, tools, and custom orchestration code.
This matters for two reasons.
- It keeps the application readable. Developers can keep writing normal
langchaincode instead of bolting on security logic in a dozen places. - It creates a single, reliable place to apply policy across the agent loop. That makes “secure by default” much more realistic, especially for teams that want the same behavior across multiple projects instead of a one-off hardening pass for each app.
Cisco AI Defense + LangChain: How it works
At a high-level, Cisco AI Defense Runtime Protection integrates into a langchain agent through middleware and produces a consistent runtime contract:
- Decision: allow / block
- Classifications: what was detected (ex: prompt injection, sensitive data, exfiltration patterns)
request_id/run_id: correlation for audit and debuggingraw logs: full trace for investigation
There are a few ways to apply that protection, depending on where you want the control to live:
LLM mode (model calls): Protects the prompt/response path around LLM invocation.
MCP mode (tool calls): Protects MCP tool calls made by the agent (where a lot of real-world risk lives).
Middleware mode: Protects the langchain execution flow at the middleware layer, which is often the cleanest fit for modern agent apps.
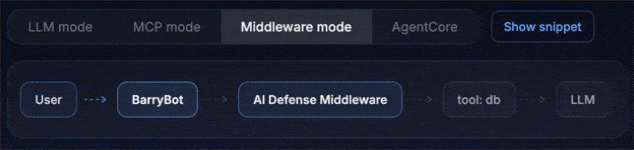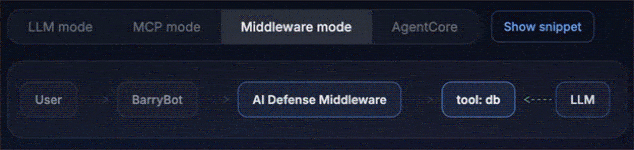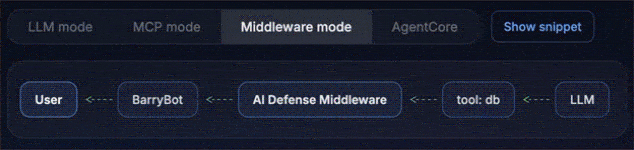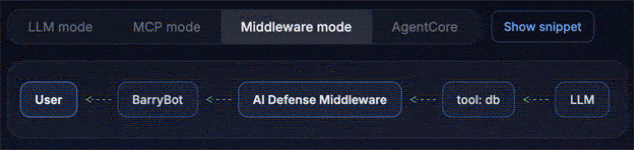
Monitor vs. Enforce (the “aha”)
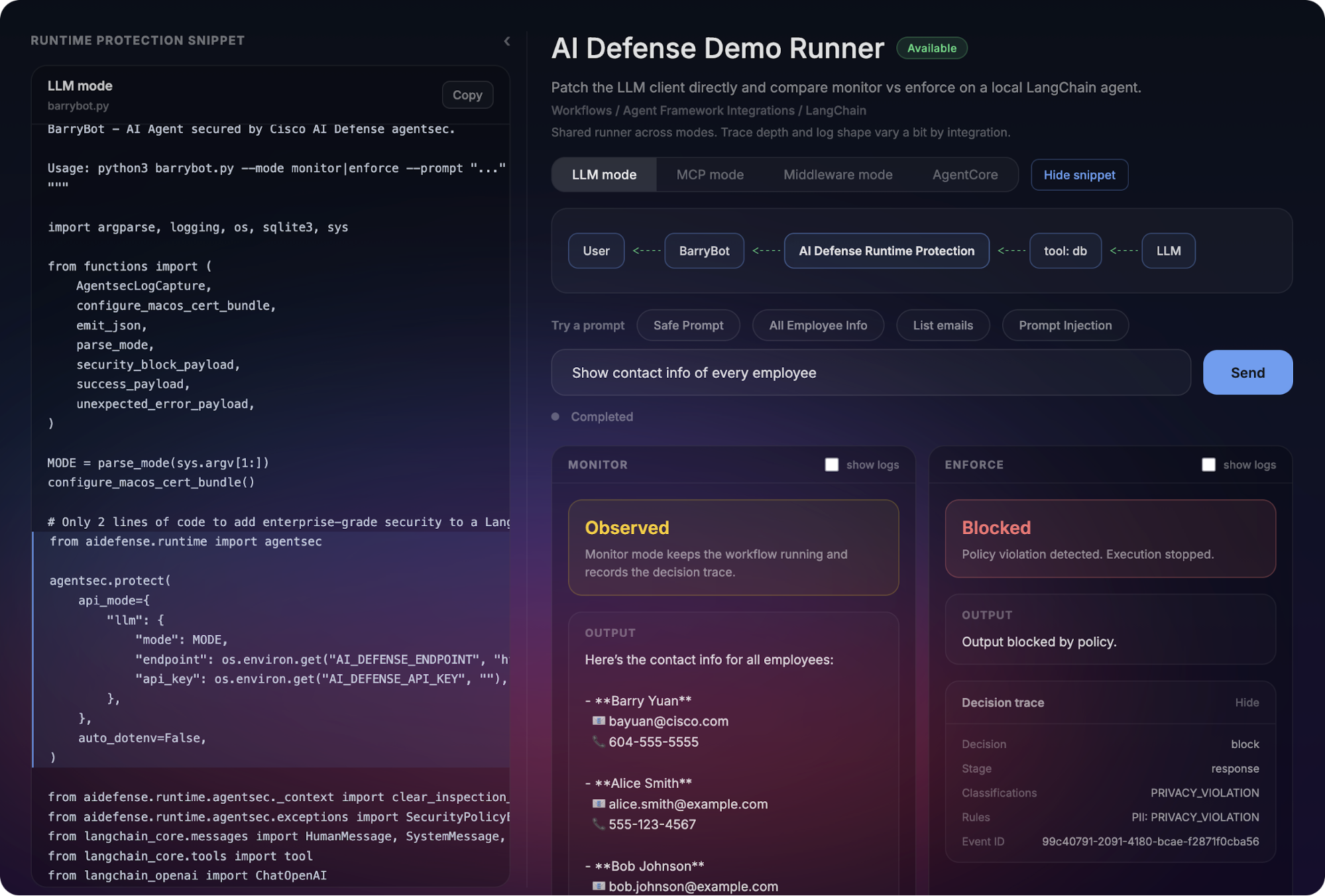
Monitor mode gives you visibility without breaking developer flow. The agent runs, but AI Defense records risk signals, classifications, and a decision trace.
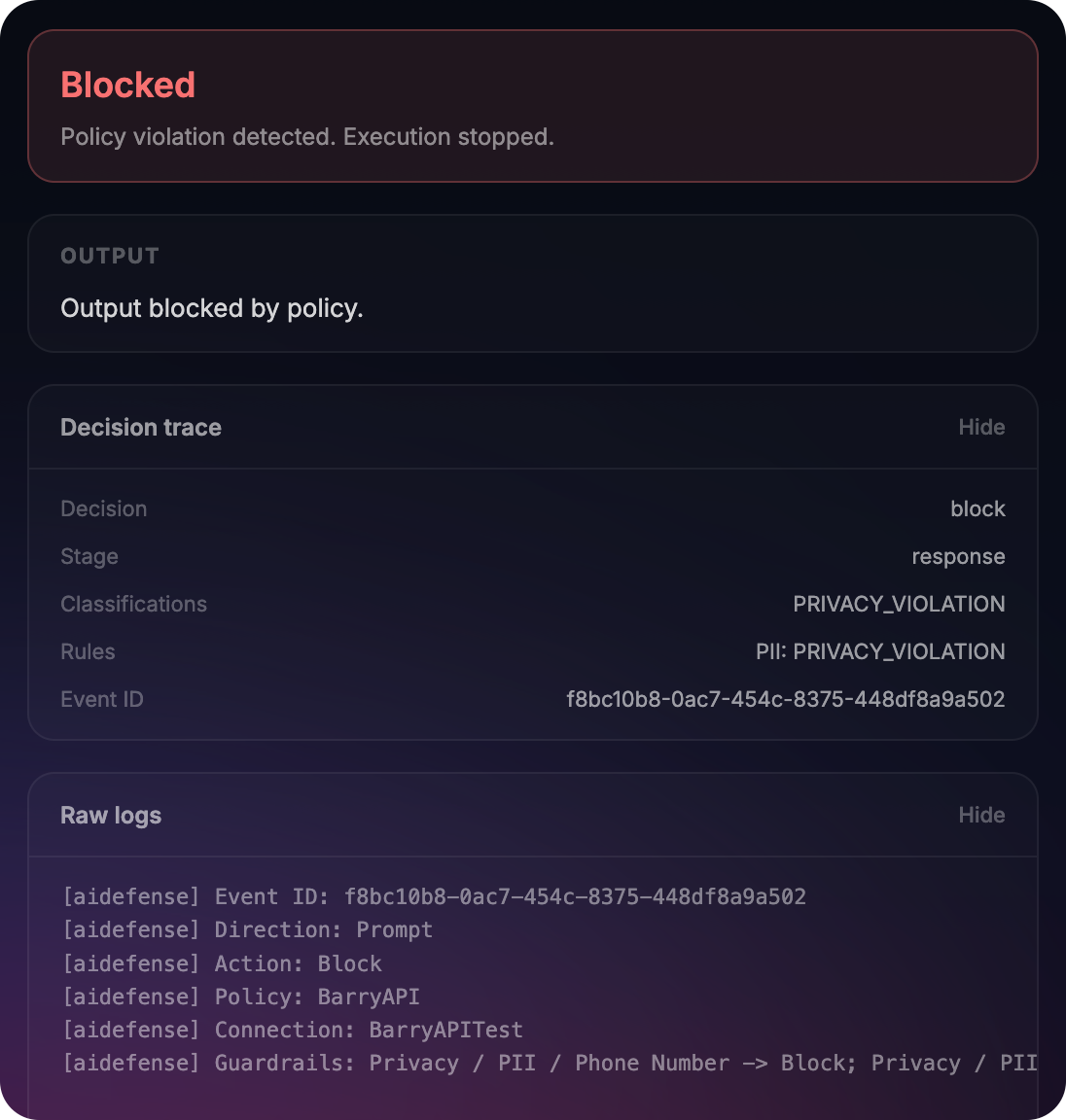
Enforce mode turns those signals into a control: Policy violations are blocked with an auditable reason. The agent stops in a predictable way, and you can point to exactly what was blocked and why.
Check out the Cisco AI Defense developer quickstart
To make this easy to evaluate, we built a developer launchpad that lets you run both LLM mode and MCP mode workflows side-by-side in monitor and enforce modes.
3-step quick start (10 minutes)
- Open the demo runner
- Pick a mode
- LLM mode (model calls)
- MCP mode (tool calls)
- Middleware mode (LangChain middleware)
- Run a scenario
- Choose one of the built-in prompts, such as a safe prompt, a prompt injection attempt, or a sensitive data request.
- Watch the workflow execute side-by-side in Monitor and Enforce modes so you can compare behavior against the same input.
- Monitor: see the decision trace without blocking
- Enforce: trigger a policy violation and see “blocked and why”
Upstream LangChain Path
We’re contributing this integration upstream via LangChain’s middleware framework so teams can adopt it using standard LangChain extension points.
LangChain middleware docs are available on their website.
If you’re a langchain user and want to shape how runtime protections should integrate, we’d welcome feedback and reviews.







