LangSmith vs Arize: AI agent observability, evals, and deployment compared
Compare LangSmith and Arize for AI agent engineering. Feature-by-feature breakdown of observability, evaluation, deployment, pricing, and migration.
June 6, 2026
LangSmith is a framework-agnostic platform for agent engineering, combining observability, evaluation, and deployment so teams can iterate quickly. It is trusted by Harvey, Clay, Cloudflare, Cisco, and millions of developers worldwide. Both LangSmith and Arize both provide tracing and evals for LLM applications and AI agents in production. However, LangSmith supports the full Agent Development lifecycle, from traces to evals to deployment, in one platform.
- Full-lifecycle agent engineering in one platform
- Production traces that feed directly into evals and improvements
- Built-in deployment for stateful agents
Get a demo of LangSmith's agent engineering platform
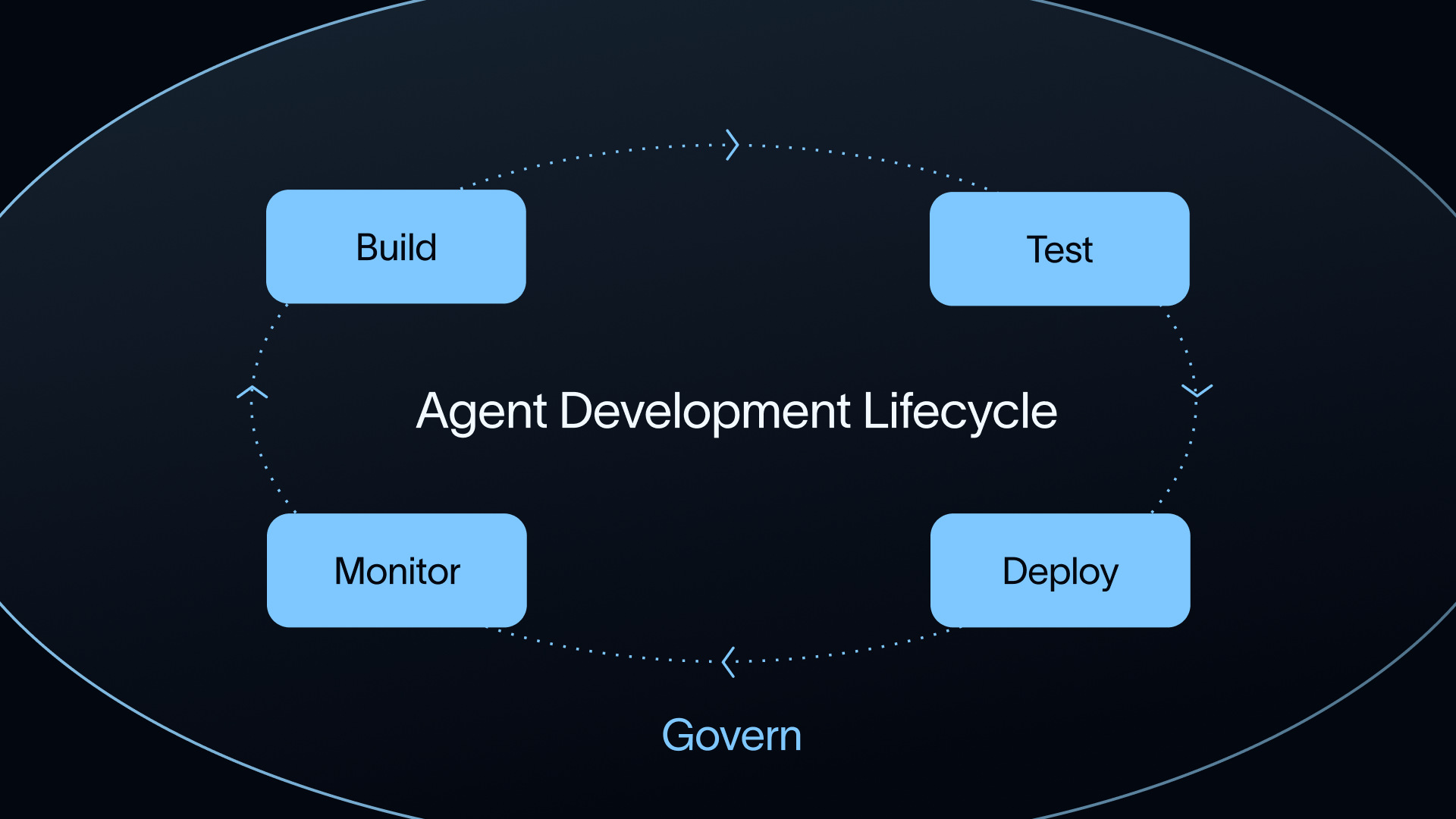
What sets LangSmith apart from Arize?
Arize earns G2 praise for intuitive navigation and responsive support. Its OpenTelemetry (aka OTel)-native instrumentation is strong, making it a capable monitoring platform for teams that span generative AI and classical ML.
The differences show up when you need more than monitoring.
Where teams hit friction with Arize
Arize is a capable platform. These are scope boundaries that matter as your AI agents grow more complex.
- Self-hosted ingest performance under sustained load: A high-priority GitHub issue reports that Phoenix's BulkInserter can open up to seven database sessions per loop iteration. That risks connection-pool exhaustion. A separate issue reports 504 errors when exporting large span datasets via
get_spans_dataframe(). (Sources: Phoenix #12358; Phoenix #11873) - Data delay for traces: After traces are ingested, there is a notable delay before data appears in Arize's project dashboard. Data appears incrementally, and complete traces aren't visible until much later. By contrast, LangSmith traces appear in seconds.
- Token counts not surfaced in REST API: An open GitHub issue notes that Phoenix tracks token counts but doesn't expose them in project-level REST endpoints, it only exposes them via span attributes and GraphQL. (Source: Phoenix #12349)
- Latency and custom instrumentation friction: A G2 enterprise reviewer from June 2025 cited latency and custom instrumentation as the platform's main downside. (Source: G2)
- Agent workflow depth perception: community commenters noted that Phoenix feels more oriented toward model monitoring than productized agent workflows. (Source: r/LLMDevs discussion, 2025)
Why choose LangSmith over Arize?
Each limitation above maps to a capability we built into LangSmith. We give you opinionated mechanics for offline and online evals, with LLM-as-a-judge built in.
LangSmith evaluators are versioned prompts with pre-templated structures, making it clear how evaluators are configured and how variables are injected. Arize’s evaluators don’t come with pre-templated prompts, making it harder to get started and understand variable injection.
LangSmith's cloud platform ingests 500K–750K spans per minute in independent load tests, processes over 100M runs per day, and serves 30K+ monthly active tenants. Our server-side logic was rewritten in Go and re-architected for large payload sizes, including audio and video.
SmithDB, our purpose-built database for agent observability, delivers industry-leading performance across every key observability workload — with P50 latencies of 92ms for trace tree loads, 400ms for full-text search, and 82ms for run filtering.
The Developer tier on LangSmith is free: one seat, 5,000 base traces/month, with production features and code evaluators included.
We designed LangSmith to cover the full application lifecycle without forcing you to stitch together separate tools: you trace and evaluate agents in one place, then deploy them with built-in persistence.
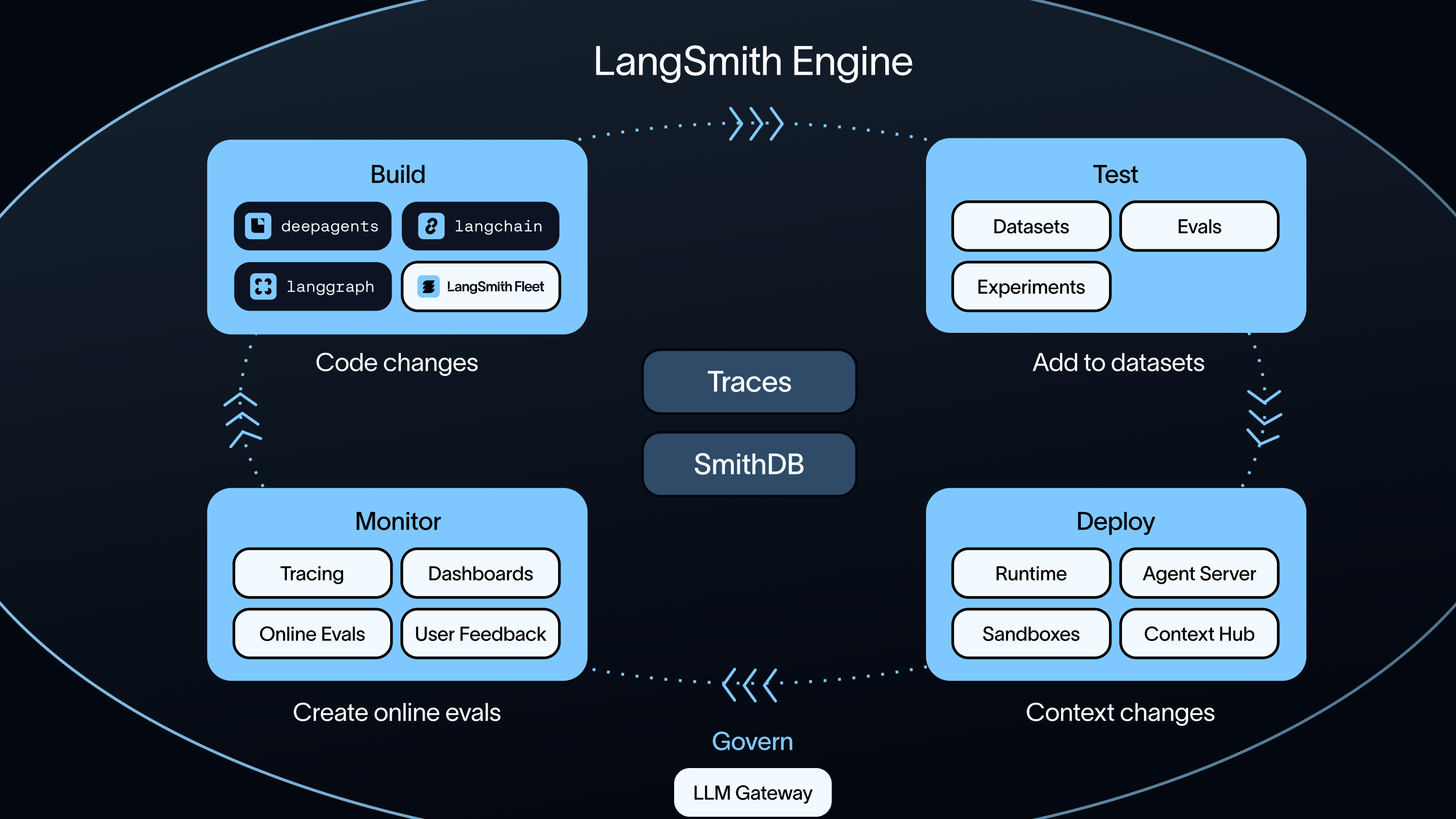
Turn production traces into improvements automatically
Most observability platforms stop at surfacing data. LangSmith goes a step further by turning that data into a repeatable improvement cycle we call the Agent Development Lifecycle.
Production traces flow into Insights, which identifies usage patterns and failure modes. Those insights become datasets. The datasets power evals. The evals then guide the next round of changes.
LangSmith also removes friction from iteration. You can pull traces straight into the Playground to test and refine prompts. In Arize, you typically need to add a trace to a dataset before you can test with it, which slows the debug and iterate loop.
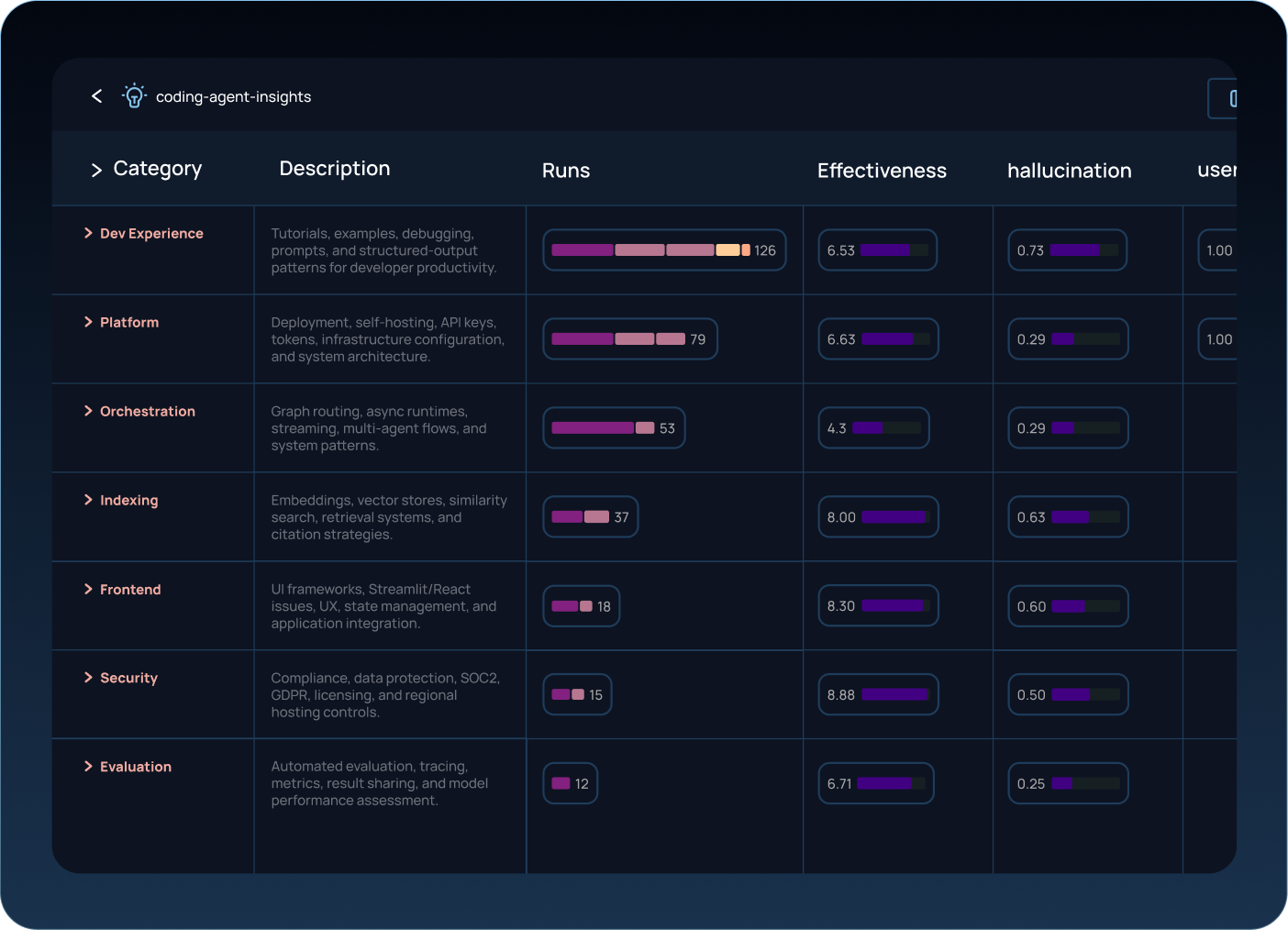
Evaluate conversations as they happen, not after
Single-turn evals miss context that matters. Did the user express frustration across the conversation? Did the agent loop on the same tool call repeatedly?
LangSmith's thread-level evaluation measures the entire interaction as one unit, because that's how your users actually experience the agent. Phoenix's open-source evaluator library runs against traces you've already collected. However, Arize AX can support online evals that score LLM outputs in real time as traces are ingested, enabling immediate monitoring, dashboards, and threshold-based alerting in production.
LangSmith evaluators also self-improve through human corrections. When domain experts provide feedback, those corrections become few-shot examples that are first-class inputs to the evaluator, continuously improving scoring accuracy. Arize lacks self-improving evaluators entirely.
Deploy stateful AI agents without a separate platform
AI agents are long-running and stateful by nature. A deep research agent runs for hours, pauses for human feedback, then resumes with full context. LangSmith Deployment has purpose-built infrastructure for these workloads: persistence and durable checkpointing, with LangSmith Studio for visual debugging. Arize is not a deployment solution, so teams using Arize typically pair it with separate hosting infrastructure.
How LangSmith has helped frontier teams
"We can pull down LangSmith traces, see how they interact with the code being executed, and make changes informed by what's actually happening. There's a loose self-improving loop: make changes, execute a graph, see the trace, pull the trace back in." (Harmonic Story)
"As we embedded AI into individual products, it became clear that siloed, vertical-specific models couldn't scale. Rippling's data model spans thousands of tables across HR, IT, finance, and global ops — with overlapping entities and shared concepts that mean entirely different things depending on context. We needed an AI-native reasoning layer that could disambiguate and operate across that entire ontology, not just optimize for one domain." (Rippling Story)
Switching from Arize to LangSmith
Moving from Arize doesn't require a rebuild, and if your team can navigate Arize, it can navigate LangSmith. The organizational UX structure (projects, traces, datasets, experiments) is nearly identical between the two platforms, so the learning curve is minimal. LangSmith is framework agnostic and works with LangGraph, the LangChain framework, Deep Agents and any other stack.
- Tracing setup: Add the
@traceablewrapper to your existing code. Most teams finish instrumentation within a day. - Dataset migration: Export your evaluation datasets and import them into LangSmith for continuity. LangSmith accepts CSV uploads directly through the UI or SDK.
- Eval mechanics: Recreate your evaluation logic using LangSmith's built-in offline and online evals, plus LLM-as-a-judge support.
- Team onboarding: Annotation Queues let domain experts review traces immediately.
- Timeline: Most teams complete migration in under two weeks. Our team supports you through the process.
When to use LangSmith vs. Arize
Where LangSmith pulls ahead
Multi-step AI agent debugging at enterprise scale
- LangSmith renders the full execution tree for each trace. You get X-ray vision into 50-step agent runs instead of linearized logs.
- Automated feedback triggers surface issues in real time. Your team can act on failures as they happen.
Domain expert review without engineering bottlenecks
- Annotation Queues put traces in front of domain experts like clinicians, lawyers, analysts, and product managers for review without requiring code access.
- Align Evaluators aligns LLM-as-a-judge scoring with expert feedback through few-shot examples.
FAQ
Does LangSmith work if we don't use LangChain or LangGraph?
Yes: LangSmith is framework-agnostic and works with any LLM application or AI agent stack, including the LangChain framework, LangGraph, Deep Agents, or your own custom setup. Add the @traceable wrapper to get full tracing regardless of your orchestration framework.
How long does it take to switch from Arize to LangSmith?
We typically see teams complete the transition to LangSmith in under two weeks by following a structured migration path. Day 1 is focused on technical instrumentation; you simply apply the @traceable wrapper to your functions across the LangChain framework, LangGraph, Deep Agents, or any other stack.
By the end of the first week, teams usually achieve evals parity by importing existing Arize datasets and mapping their evaluation mechanics to our built-in LLM-as-a-judge scorers. This timeline allows for a full week of parallel testing to validate your AI agent performance against historical benchmarks before the final production cutover.
Will we lose historical data when switching?
You keep any datasets you export from Arize. LangSmith starts collecting new traces immediately after instrumentation, and historical Arize traces stay in your Arize account.
What does LangSmith cost?
Plans start at $0/month on the Developer plan: one user seat and 5,000 base traces included.
The Plus plan is $39/seat/month with 10,000 base traces and one dev-sized deployment, which we’ve optimized for testing and low-concurrency workloads. For organizations requiring high-volume throughput and higher resource limits, we offer a tailored Enterprise tier. Enterprise pricing is custom. See full pricing details.
Does Arize offer anything LangSmith doesn't?
Yes: Arize supports traditional ML and computer vision monitoring alongside generative AI. If your team monitors classical models and LLM agents on one platform, that's a big benefit of Arize.
Arize also offers Phoenix as a free, self-hosted source-available tool. It’s worth noting that Phoenix and Arize’s enterprise product (AX) have incompatible SDKs, so there is no seamless migration path from the free tool to the paid platform. Phoenix also lacks production-grade capabilities like online evals and monitoring. Teams who start on Phoenix expecting a smooth upgrade to AX will need to re-instrument.
Arize has an AI assistant, Alyx. How does LangSmith compare?
Arize’s Alyx is a strong conversational interface for onboarding and rapid prototyping. It can generate synthetic traces, test prompts, and create evaluators through chat.
LangSmith takes a different approach, with two complementary AI capabilities. Insights produces structured, repeatable analysis across large volumes of production traces, and you can run it via the UI or SDK for systematic monitoring. Chat supports in-platform assistance for real-time trace analysis and debugging.
The core difference is intent. Alyx is designed for interactive exploration. LangSmith’s AI tools are designed to support production decisions in a consistent, repeatable way.
Can we use LangSmith for evaluation only, without switching our tracing?
You can: LangSmith's evaluation mechanics work independently. Teams often start with evals and expand to tracing and deployment over time.
See what full-lifecycle agent engineering looks like
LangSmith gives you tracing and evals with built-in deployment and it works with the LangChain framework, LangGraph, Deep Agents, as well as any other agent stack.
Get started today for free or get a demo of LangSmith's agent engineering platform.