LangSmith vs Datadog: Which platform fits your AI agent engineering stack?
Compare LangSmith and Datadog for AI agent observability, evaluation, and deployment. See feature differences, pricing, and which platform fits your needs.
June 6, 2026
LLM observability helps you trace and debug what happens inside an AI agent. It shows not only whether the agent responded, but also whether the reasoning was sound. As teams move agents into production, this tooling becomes a foundational part of the engineering stack.
Datadog is great for infrastructure observability, and it does that job well. But building, evaluating, and continuously improving AI agents requires a purpose-built platform. LangSmith closes that loop. And if you already use Datadog, you can use both.
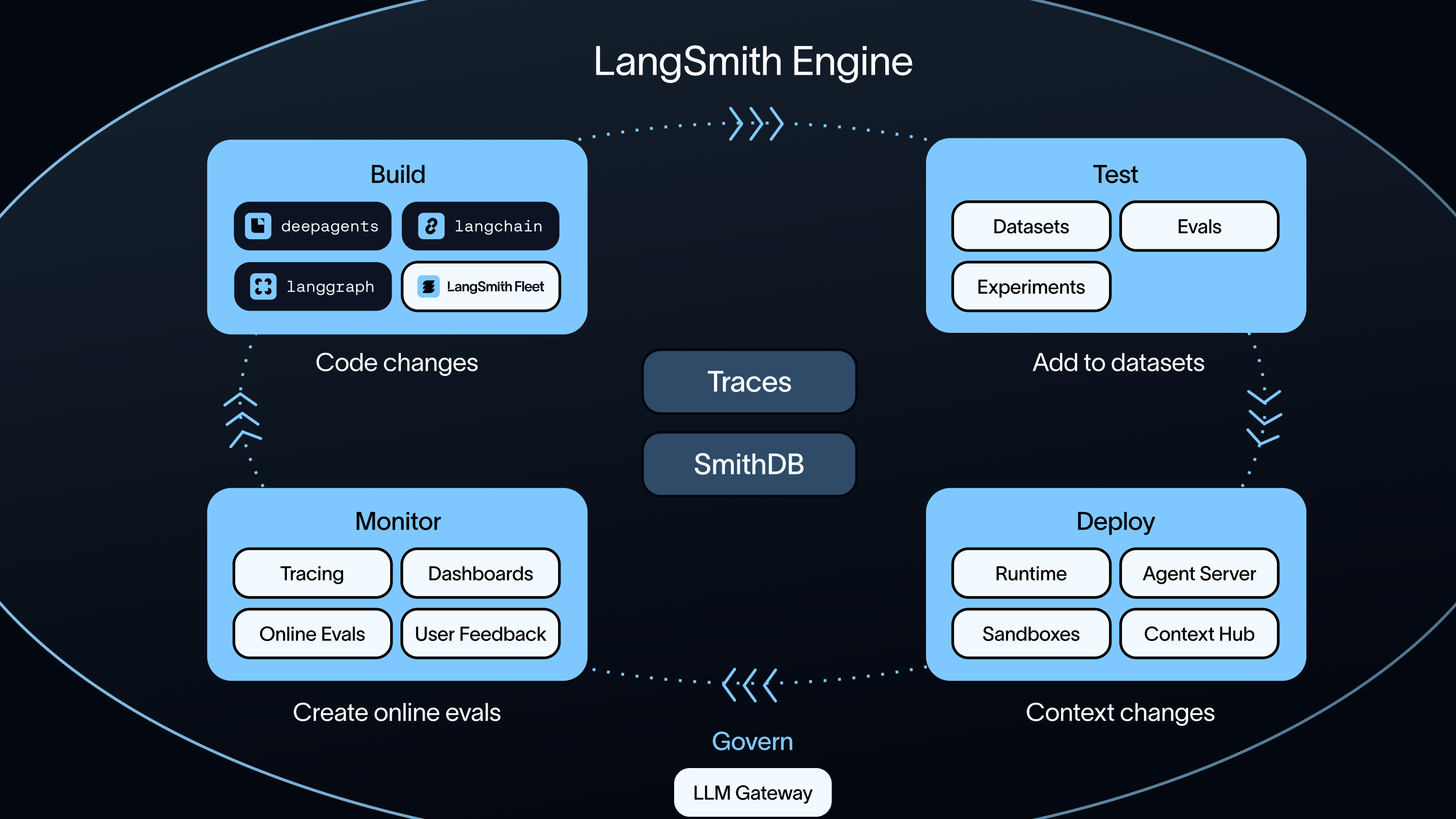
LangSmith takes a different approach than Datadog, it is built specifically for AI agent engineering, including tracing, evals, human review, and managed deployment in a single platform. LangSmith is framework-agnostic, but also works with the LangChain framework, LangGraph, Deep Agents, and any other stack.
- Agent-native tracing across every reasoning step
- Offline and online evals built into your production loop
- Framework-agnostic instrumentation that fits your stack
- Prompt Hub & Registry for versioned prompt management
Get a demo of LangSmith's agent engineering platform
What sets LangSmith apart from Datadog?
Datadog is the standard for infrastructure observability. It is industry-standard monitoring for services, infra, and apps at scale. It provides unified visibility across your entire stack (APM, RUM, logs, infra metrics, databases), mature alerting with SLOs and incident management (including Watchdog anomaly detection and on-call workflows), and deep enterprise infrastructure integrations across AWS, Azure, GCP, and Kubernetes. The question is whether an infrastructure-first platform gives your team agent-specific depth.
LangSmith gives your team what we call the feedback layer: a closed loop between human review, automated evaluation, and production signals that infrastructure platforms don't provide.
First, Annotation Queues let domain experts review and correct agent outputs directly. Those corrections don't sit in a spreadsheet. They feed into Align Evals, which translates human judgment into LLM-as-judge scoring criteria that run automatically on every future trace. And trace-level and thread-level signals from production feed back into your datasets, so your evals stay calibrated against real user behavior, not synthetic benchmarks. LangSmith also offers LangSmith Engine, which uses an agent to help you move through this loop faster. Engine prioritizes your agent’s issues and generates a PR for your approval. It also creates evals so the regression doesn’t happen again.
Datadog captures what happened. The feedback layer from a platform like LangSmith helps your team make what happens next better.
Infrastructure-first platforms like Datadog tend to treat AI outputs the same way they treat any other microservice, as another stream of signals in a dashboard where every metric carries the same weight. But non-deterministic outputs need different evaluation criteria like evals, human review, and production debugging designed specifically for non-deterministic AI work.
Datadog capability assessments based on 2026 Datadog LLM Observability documentation. Features marked ✗ were not documented as available at the time of review.
Where teams hit friction with Datadog for AI agent work
Datadog is a strong infrastructure platform. These friction points surface specifically when teams use it for agent-level observability and evaluation.
Cost predictability at scale
G2 reviewers have flagged unpredictable costs as a pain point when combining multiple Datadog products. LangSmith pricing starts at $0/month and scales on usage without cross-product bundling surprises.
Learning curve for agent-focused teams
G2 reviewers have described the UI as cluttered or overwhelming for new users. Teams focused on agent debugging rather than infrastructure monitoring find that breadth adds friction.
JS tracer stability in AI workflows
One developer reported crashes and empty metrics when tracing Anthropic streaming responses with extended thinking (GitHub #7890).
Agent-specific depth vs. infrastructure breadth
Datadog has been the default observability platform for engineering teams long before LLM applications existed. It offers standard LLM tracing, token usage, cost, and latency monitoring, plus light evaluation tooling. But it has limited agentic-driven capabilities and no automatic feedback loops connecting traces to agent improvements. For most teams evaluating LangSmith, the question isn't which one to choose, it's what LangSmith adds to a stack where Datadog is already running.
One commenter on r/learnmachinelearning described Datadog as "excellent infra observability that happens to support LLMs" but "not really LLM-native" (Reddit, April 2025). The platform is oriented toward engineering teams monitoring infrastructure, which can leave non-technical reviewers without a clear path into the workflow. Your team can decide whether that tradeoff fits your stack.
Why choose LangSmith over Datadog?
The friction points above point to a structural difference. Datadog extends infrastructure monitoring into AI. LangSmith starts with the behavior of AI systems themselves.
Tracing is built for non-deterministic reasoning, not request-response logs. Evals are part of the production loop, not an afterthought. Domain experts can review outputs, flag failures, and improve quality without waiting on engineering.
Tracing, evals, and human review aren’t layered on, but are the foundation.
See every reasoning step your agent takes
Both platforms offer solid tracing UIs, but the real difference is what you can do with the data after a trace is captured. LangSmith turns traces into an improvement loop by connecting them to evals, Annotation Queues, Insights Agent, Prompt Hub, and Deployments.
LangSmith also renders the full execution tree for every agent run, including prompts, intermediate reasoning steps, tool calls, and outputs, so your team can see exactly why an agent made a given decision. If you want to observe the cognitive architecture in action, LangSmith shows it natively.
Close the loop from production traces to better evals
We built evals into the core of LangSmith. Your team can run offline evals as regression tests on curated datasets. Online evals score live production traffic. Thread-level evaluation covers full conversations. The agent improvement loop connects these pieces: production traces feed Insights, which surfaces usage patterns, which become datasets, which drive evals, which improve your agents. LangSmith Engine moves through this loop for you.
"With LangSmith, Podium reduced engineering intervention by 90% and improved agent F1 from 92% to 99% using trace-driven dataset curation and offline evals." (Podium Story)
Bring domain experts into the agent improvement loop
Agent development requires input from people outside engineering. Annotation Queues gives agentic engineers, data scientists, PMs, deployment teams, business analysts, and domain experts a direct path to review and correct complex traces without needing engineering support. Align Evals then translates that human feedback into reproducible evaluation criteria, so subjective quality judgments become automated checks. As noted in the breadth limitation above, Datadog's platform focuses on engineering teams monitoring infrastructure. Non-technical reviewers aren't as strong of a fit for the core workflow.
How LangSmith has helped frontier teams
"We can pull down LangSmith traces, see how they interact with the code being executed, and make changes informed by what's actually happening. There's a loose self-improving loop: make changes, execute a graph, see the trace, pull the trace back in." (Harmonic Story)
"As we embedded AI into individual products, it became clear that siloed, vertical-specific models couldn't scale. Rippling's data model spans thousands of tables across HR, IT, finance, and global ops — with overlapping entities and shared concepts that mean entirely different things depending on context. We needed an AI-native reasoning layer that could disambiguate and operate across that entire ontology, not just optimize for one domain." (Rippling Story)
Better Together: LangSmith + Datadog
Our team has helped organizations transition from infrastructure-first monitoring to agent-native observability.
Add the traceable wrapper to your existing code. LangSmith is framework agnostic, but also works well with the LangChain framework, LangGraph, and Deep Agents. Your existing Datadog traces stay in Datadog. New traces begin populating LangSmith immediately.
Fan out traces to LangSmith and Datadog simultaneously over OTel with no extra instrumentation. Click into a LangSmith agent trace from Datadog, and click back into a Datadog infra trace from LangSmith. Each platform handles what it does best.
Start building datasets from production traces on day one. Most teams run their first evals within the first week. Engineers, PMs, domain experts, and analysts can access Annotation Queues and dashboards without infrastructure training.
Timeline
Most teams are fully operational on LangSmith within one to two weeks. Typically starting with instrumentation and ending with datasets and evals running against live production traffic. Engineers, PMs, and domain experts can access Annotation Queues and dashboards without any additional infrastructure work.
When to use LangSmith vs. Datadog
Ops teams stay in Datadog. AI engineers, PMs, data scientists, domain experts, business analysts, and human reviewers all collaborate in LangSmith. OTel makes running both seamless.
Where LangSmith pulls ahead
Debugging non-deterministic agent failures in production
Your agent passes testing but fails on real user inputs. LangSmith's execution tree shows every reasoning step, so you find the root cause in minutes instead of days.
Insights Agent autonomously surfaces usage patterns, failure modes, and quality trends across your traces. It identifies what's going wrong, how often, and where, so your team can focus on fixes instead of hunting through logs.
Improving agent quality with cross-functional review
A clinician spots an incorrect medical summary in Annotation Queues and flags it. Engineers don’t need to manage the queue directly; the domain expert handles review directly.
Align Evals converts those corrections into automated scoring criteria that run on every future trace.
LangSmith's Threads & Messages capability provides multi-turn conversation views and evaluations, letting product managers track quality trends across full agent interactions end-to-end and catch regressions before users report them.
Deploying stateful agents that run for hours
LangSmith Deployment handles persistence, task queues, and state across interruptions for long-running agents. It supports Assistants, Runtime Config, MCP, A2A, horizontal scaling, and 30+ API endpoints.
Human-in-the-loop workflows let agents pause for approval and resume without losing context. LangSmith Studio provides visual debugging for stateful execution, which can be harder to implement in serverless architectures without additional infrastructure.
FAQ
Can LangSmith replace Datadog for AI agent observability?
For agent-level tracing and evals, LangSmith covers the application's entire lifecycle from debugging to deployment. If you also need server-level APM and infrastructure monitoring, you'd keep Datadog for that layer alongside LangSmith.
How long does it take to switch from Datadog to LangSmith?
Many teams can start collecting traces within a day, especially if they’re already using LangChain. Full onboarding, including eval setup and team access, typically takes one to two weeks.
Will I lose my existing Datadog trace data?
Your Datadog traces remain in Datadog under its retention policies. LangSmith begins collecting new traces once you add instrumentation. The two systems operate independently and track different layers of your application.
Does LangSmith work with frameworks other than LangChain?
LangSmith is framework-agnostic. It works with the LangChain framework, LangGraph, Deep Agents, and any other LLM stack. You instrument with the traceable wrapper regardless of your framework choice.
What does LangSmith cost compared to Datadog?
LangSmith starts at $0/month on the Developer plan with a fully functional free tier. Datadog LLM Observability starts at $8 per 10K monitored requests per month (billed annually), with a 100K request monthly minimum. This puts the floor at $80 per month after the free trial. Datadog bills per individual LLM call, not per user interaction, so multi-step agents that trigger 10-15 LLM calls per request will see costs multiply quickly. See LangSmith pricing.
Do LangSmith and Datadog support sensitive data handling?
Both platforms support sensitive data handling. LangSmith provides PII masking via LANGSMITH_HIDE_INPUTS/LANGSMITH_HIDE_OUTPUTS env vars, rule-based regex anonymization, per-field handlers, and integrations with Microsoft Presidio and Amazon Comprehend. Datadog LLM Observability bundles sensitive data scanning and redaction through its Sensitive Data Scanner.
Start building with agent-native observability
Ship agents your team can actually trust in production. Start for free on the Developer plan, instrument your first agent in an afternoon, and measure the impact within a sprint. Teams that move to LangSmith typically report faster root-cause resolution on production failures, higher agent quality scores after the first round of evals, and shorter review cycles once domain experts join Annotation Queues.
If you are evaluating agent observability right now, the fastest way to decide is to run LangSmith alongside your current setup on one live agent and compare what each platform surfaces.
- Start free: Create an account and send your first trace today, no credit card required.
- Talk to our team: Get a tailored walkthrough for your stack, including migration support if you are coming from Datadog.
- See it on your data: Bring a production trace to the demo and we will show you evals, Annotation Queues, and deployment live.
Start free with LangSmith or book a demo with our agent engineering team.