8 LLM Observability Tools to Monitor & Eval AI Agents
A breakdown of the leading 8 LLM observability platforms for agent debugging, tracing, and evaluation.
8 LLM Observability Tools to Monitor & Eval AI Agents
Error logs tell you what broke. They don't flag hallucinations or when the model drifts from its intended behavior.
Basic monitoring catches obvious failures. The harder problem to solve is building workflows where subject matter experts can review specific runs, rate output quality, and add context that engineering teams can act on.
The best observability tools turn this feedback into a structured process, not scattered Slack alerts and spreadsheets.
This guide compares eight LLM observability platforms on their tracing, evaluation, and collaboration features.
While some focus on traditional infrastructure-level monitoring, others help you answer the harder question: whether your LLM agent actually produces good outputs for your specific use case.
Summary
- Choose LangSmith if you need comprehensive agent debugging, observability, and evals, with structured workflows for domain experts to review and annotate production traces.
- Choose Datadog LLM Observability if you need unified infrastructure and LLM monitoring within an existing Datadog stack.
- Choose Langfuse if you need an open-source, self-hostable platform combining observability with prompt management.
- Choose Helicone if you need a low-latency proxy that adds observability and caching with minimal code changes.
The bottom line: The best observability tools go beyond showing errors and create feedback loops where subject matter experts can contribute domain knowledge that engineers can actually use.
Get a demo of LangSmith's agent engineering platform
The best LLM observability tools at a glance
What to look for in an LLM observability tool?
Catching errors is table stakes. The real challenge is knowing when outputs are technically valid but wrong for your domain. The best LLM observability tools surface these ambiguous cases for human review.
Tracing depth matters. You need visibility into every step of complexagent workflows: tool calls, retrieved documents, and intermediate reasoning. Black-box monitoring doesn't work for multi-step agents.
The best tools close the loop between production and development. They let domain experts annotate specific runs, then turn that feedback into evaluation datasets.
How we evaluated these tools
We analyzed official documentation, GitHub repositories, and public pricing pages for each platform. We gathered community sentiment from Reddit, Hacker News, and GitHub discussions, because real user feedback often surfaces nuances that official docs don't.
For this analysis, we focused on tracing, evaluation features, integration flexibility, and collaboration workflows.
LangSmith is built by LangChain, who publishes this guide. We believe in LangSmith, but we have done our best to give every tool here a fair assessment. If LangSmith is not the right fit, one of these alternatives probably is.
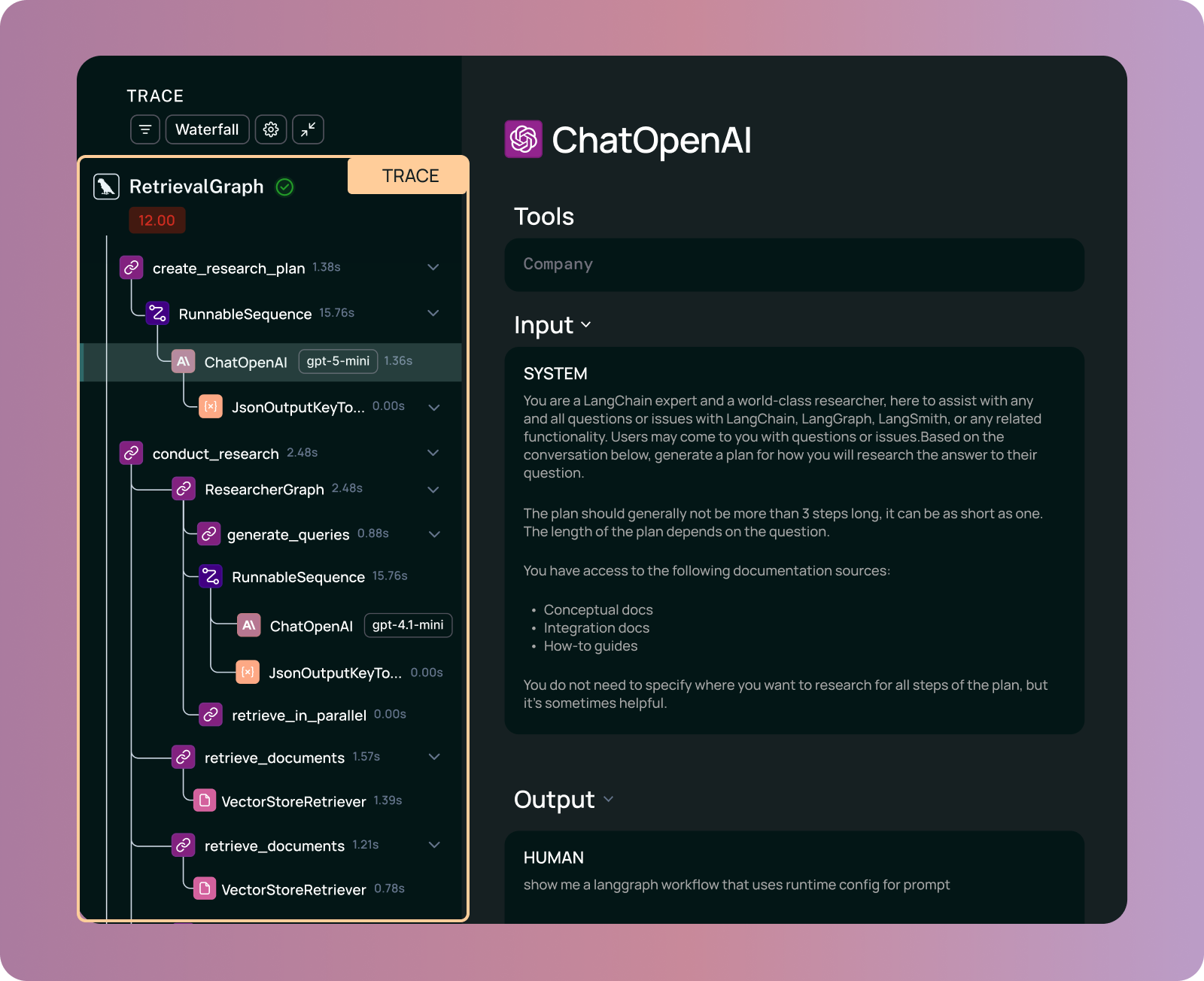
LangSmith
What is LangSmith?
Quick Facts:
- Type: Observability and Evaluation Platform
- Company: LangChain
- Pricing: Free tier available; Plus at $39/seat/month; customer Enterprise pricing
- Open Source: No
- Website: https://smith.langchain.com
LangSmith is a unified agent engineering platform that provides observability, evaluations, and prompt engineering for any LLM application or AI agent. LangSmith is framework agnostic and works with any agent stack. It works with any framework, such as: OpenAI SDK, Anthropic, custom implementations, LangChain, or LangGraph.
The platform creates high-fidelity traces that render the complete execution tree of an agent. You see tool selections, retrieved documents, and exact parameters at every step.
LangSmith turns observability into a collaborative workflow. Annotation Queues let subject matter experts review, label, and correct complex traces. This domain knowledge flows directly into evaluation datasets, creating a structured feedback loop between production behavior and engineering improvements.
LangSmith also allows you to run offline evaluations on datasets, or run online evaluations on production traffic. The platform allows for automated scoring performance with evaluators, including LLM-as-judge.
Who should use LangSmith?
- Engineering teams building complex agents or multi-step workflows who need deep visibility into execution steps.
- Teams where domain experts (not just engineers) need to review and rate LLM outputs through annotation and evaluation workflows.
- Organizations running millions of traces per day who need cost and latency attribution at the step level.
Standout features
- Full-stack tracing that captures the "internal monologue" of agents, including tool calls, document retrieval, and model parameters.
- Polly, an embedded AI debugging assistant that analyzes traces and answers natural language questions like "Why did the agent enter this loop?"
- Annotation Queues that create structured workflows for human experts to review, label, and correct production traces.
- LLM-as-a-judge evaluators that automatically grade thousands of historical runs using custom criteria.
- Multi-turn evaluation support measuring agent performance across entire conversation threads.
- Insights Agent that auto-categorizes behavior patterns and prioritizes improvements by frequency and impact.
Pros and cons
FAQ
Q: Does LangSmith only work with LangChain applications? No. LangSmith is a standalone platform that works with any LLM framework, including OpenAI SDK, Anthropic, and custom implementations. It uses a traceablewrapper for automatic instrumentation regardless of your stack.
Q: How does LangSmith handle high-volume production traffic? LangSmith processes millions of traces per day for enterprise customers. The platform offers 14-day retention for base traces and 400-day extended retention, with volume-based pricing that scales with usage.
Q: What evaluation approaches does LangSmith support? LangSmith supports offline evals (testing known scenarios before production), online evals (testing over real-time production data), and multi-turn evaluations for conversation-based agent applications. You can use LLM-as-judge evaluators or human annotation workflows.
Q: Can subject matter experts who aren't engineers use LangSmith? Yes. Annotation Queues are designed for domain experts to review specific traces, rate output quality, and add context without needing engineering skills. This feedback integrates directly into evaluation datasets.
Datadog
What is Datadog LLM Observability?
Quick Facts:
- Type: Observability
- Company: Datadog, Inc.
- Pricing: Contact for pricing
- Open Source: No
- Website: https://www.datadoghq.com/product/llm-observability/
Datadog LLM Observability extends Datadog's existing monitoring platform to cover LLM applications. It correlates LLM spans with standard APM traces, showing how model latency affects overall application performance.
The platform supports agentless deployment via environment variables. This makes it accessible for serverless environments. Teams can view LLM performance alongside infrastructure metrics, error rates, and traditional application monitoring. Datadog provides Jupyter notebook examples for common patterns like RAG pipelines and agents.
Who should use Datadog LLM Observability?
- Teams already invested in the Datadog ecosystem who want to add LLM monitoring without adopting a new platform
- Organizations that prioritize correlating LLM performance with infrastructure metrics
Standout features
- Correlation between LLM spans and standard APM traces for end-to-end latency analysis
- Agentless deployment mode for serverless and restricted environments
- Pre-built Jupyter notebooks demonstrating RAG pipeline and agent instrumentation
- Automatic instrumentation of LangChain applications via
dd-trace-py
Pros and cons
FAQ
Q: Do I need the Datadog Agent to use LLM Observability? No. Datadog supports an agentless mode via environment variables, though running the full agent provides additional capabilities.
Q: How does Datadog LLM Observability compare to dedicated LLM tools? Community feedback suggests it excels at infrastructure correlation but lacks the depth of evaluation and annotation features found in purpose-built LLM platforms. It's best for teams prioritizing unified monitoring over specialized LLM workflows.
Q: What metadata can I attach to LLM spans? Datadog supports basic tags like temperature and model parameters. Users note that metadata support is less flexible than some dedicated alternatives.
Q: Is pricing publicly available? No. Contact Datadog sales for pricing information. Community members have expressed concerns about potential cost increases at scale.
Lunary
What is Lunary?
Quick Facts:
- Type: Observability & Prompt Management Platform
- Company: Lunary LLC
- Pricing: Free tier (10k events/month); Team and Enterprise tiers contact for pricing
- Open Source: Yes (Apache-2.0)
- Website: https://lunary.ai
Lunary is a lightweight observability platform focused on RAG pipelines and chatbots. Setup takes about two minutes. It offers SDKs for JavaScript (Node.js, Deno, Vercel Edge, Cloudflare Workers) and Python.
The platform provides specialized tracing for retrieval-augmented generation, including embedding metrics and latency visualization. The generous free tier (10k events/month with 30-day retention) makes Lunary accessible for early-stage projects. Its open-source core (Apache-2.0) allows self-hosting, though some features require Enterprise licensing.
Who should use Lunary?
- Teams building RAG pipelines or chatbots who need cost-effective observability without enterprise complexity
- Startups and small teams looking for a generous free tier to get started
- Developers working with JavaScript runtimes like Deno, Vercel Edge, or Cloudflare Workers
Standout features
- Rapid two-minute integration via lightweight SDKs
- Specialized RAG tracing with embedding metrics and latency heatmaps
- JavaScript SDK designed for compatibility with LangChain JS
- Generous free tier with 10k events/month and 30-day retention
Pros and cons
FAQ
Q: What JavaScript runtimes does Lunary support? Lunary's JavaScript SDK works with Node.js, Deno, Vercel Edge, and Cloudflare Workers.
Q: Can I self-host Lunary? The core is open source under Apache-2.0, but convenient Docker/Kubernetes configurations and some compliance features require an Enterprise license.
Q: Does Lunary support exporting traces for fine-tuning? Users have reported gaps in dataset integration for exporting traces to fine-tuning workflows. Check current documentation for the latest capabilities.
Q: What's included in the free tier? 10k events/month, 3 projects, and 30 days of log retention.
Helicone
What is Helicone?
Quick Facts:
- Type: LLM Observability & AI Gateway
- Company: Helicone, Inc.
- Pricing: Free tier (10k requests/month); Pro tier with 7-day trial; Enterprise contact sales
- Open Source: Yes (Apache-2.0)
- Website: https://www.helicone.ai
Helicone is a proxy-based observability solution. It sits between your application and LLM providers. Swap your API's base URL, and you gain observability, caching, and cost tracking with minimal code changes.
The platform adds negligible latency overhead according to Helicone’s own docs, making it suitable for production workloads.
The AI Gateway supports 100+ models across OpenAI, Azure OpenAI, Anthropic, AWS Bedrock, Gemini, and more. Intelligent caching and automatic failover help reduce API costs and improve reliability. The fully open-source core supports managed cloud, self-hosted Docker, and enterprise Helm chart deployments.
Who should use Helicone?
- Teams wanting observability without complex SDK integration
- Organizations prioritizing low latency overhead in production
- Teams needing caching and failover capabilities alongside monitoring
- Developers who prefer proxy-based approaches over code instrumentation
Standout features
- One-line integration by swapping the API base URL
- Low latency overhead suitable for production
- Intelligent caching and automatic failover across providers
- Support for 100+ models via unified gateway
- Fully open-source core with flexible deployment options
Pros and cons
FAQ
Q: How much latency does Helicone add? Negligible latency overhead, which users report is acceptable for most production workloads.
Q: What LLM providers does Helicone support? OpenAI, Azure OpenAI, Anthropic, AWS Bedrock, Gemini, Ollama, Vercel AI, Groq, and 100+ additional models.
Q: Can I self-host Helicone? Yes. The open-source core supports Docker and Helm chart deployments.
Q: Does Helicone work with LangChain? Yes. Helicone provides a LangChain provider that routes calls through its gateway while maintaining observability and caching features.
Langfuse
What is Langfuse?
Quick Facts:
- Type: LLM Engineering Platform
- Company: Acquired by Clickhouse. Continued product investment is uncertain
- Pricing: Free tier (50k units/month, 2 users); Enterprise from $2,499/month
- Open Source: Yes (MIT, except ee folders)
- Website: https://langfuse.com
Langfuse combines observability, prompt management, and evaluations in a single platform. The MIT-licensed core makes it popular with teams wanting full control over their data through self-hosting.
Automated instrumentation via callback handlers captures traces without modifying business logic. Community adoption is strong, with over 21,000 GitHub stars. The platform supports OpenAI SDK, LangChain, LlamaIndex, LiteLLM, Vercel AI SDK, Haystack, and Mastra.
Who should use Langfuse?
- Teams seeking an open-source, self-hostable alternative to proprietary platforms
- Organizations wanting observability, prompt management, and evaluations in one place
- Developers using Python or TypeScript who value drop-in SDK integration
Standout features
- Unified platform combining observability, prompt management, and evaluations
- MIT-licensed core with Docker-based self-hosting options
- Automated instrumentation via LangChain callback handlers
- Support for multiple frameworks: OpenAI SDK, LlamaIndex, LiteLLM, Vercel AI SDK, Haystack, Mastra
- 21,000+ GitHub stars as of February 2026, indicating strong community adoption
Pros and cons
FAQ
Q: Is Langfuse fully open source? The core is MIT-licensed. Enterprise features in ee folders have separate licensing. Check the repository for current details.
Q: What languages does Langfuse support? Native SDKs exist for Python and TypeScript. Other languages require building wrappers around the API.
Q: How does self-hosting work? Langfuse provides Docker-based deployment options. Users report occasional bugs in the self-hosted version, so factor in maintenance time.
Q: Can I use Langfuse with LangChain? Yes. Langfuse provides a callback handler for automated instrumentation of LangChain applications.
TruLens
What is TruLens?
Quick Facts:
- Type: Observability & Evaluation for LLM Applications
- Company: TruEra (Acquired by Snowflake)
- Pricing: Open source (free); commercial/enterprise contact for pricing
- Open Source: Yes (MIT)
- Website: https://www.trulens.org
TruLens focuses on systematic evaluation of RAG pipelines. It uses the "RAG Triad" framework: Context Relevance, Answer Relevance, and Groundedness. These metrics measure whether retrieved context is relevant, whether answers address the question, and whether responses are grounded in provided context.
The platform integrates with experiment tracking tools like Weights & Biases. Teams can log evaluation tables and A/B test model-prompt combinations. TruLens provides "chain-aware" feedback functions that capture metadata and intermediate steps better than ad-hoc evaluation scripts.
Who should use TruLens?
- Teams building RAG applications who need structured evaluation metrics
- ML engineers who want to integrate evaluation with experiment tracking platforms like Weights & Biases
- Organizations focused on measuring groundedness and context relevance specifically
Standout features
- RAG Triad evaluation framework: Context Relevance, Answer Relevance, Groundedness
- Chain-aware feedback functions capturing intermediate steps and metadata
- Integration with Weights & Biases for experiment tracking
- OpenTelemetry support for broader observability integration
Pros and cons
FAQ
Q: What is the RAG Triad? Three metrics for evaluating RAG pipelines: Context Relevance (is the retrieved context relevant?), Answer Relevance (does the answer address the question?), and Groundedness (is the response grounded in the provided context?).
Q: How does TruLens handle false positives in evaluation? Similarity-based metrics can sometimes yield high scores for contextually incorrect outputs.
Q: Does TruLens integrate with LangChain? Yes, though as a community-supported integration. TruEra provides a migration guide for incorporating TruLens into LangChain v1.x applications.
Q: Is TruLens free? The open-source library is free under MIT license. Commercial/enterprise pricing requires contacting TruEra.
Arize Phoenix
What is Arize Phoenix?
Quick Facts:
- Type: AI Observability & Evaluation
- Company: Arize AI, Inc.
- Pricing: Open source (free self-hosted); AX Free tier (25k spans/month); AX Pro/Enterprise contact sales
- Open Source: Yes (Elastic License 2.0)
- Website: https://phoenix.arize.com/
Arize Phoenix emphasizes local-first, notebook-friendly observability. It runs locally, in Jupyter notebooks, or via Docker with zero external dependencies. Privacy-focused teams find this attractive.
The platform uses OpenInference (OpenTelemetry-based) instrumentation to support multiple frameworks without vendor lock-in. Phoenix supports LlamaIndex, LangChain, Haystack, DSPy, and smolagents. The notebook-first experience lets ML engineers trace and visualize data directly during experimentation, shortening feedback loops before production deployment.
Who should use Arize Phoenix?
- ML engineers who work primarily in Jupyter notebooks and want observability during experimentation
- Privacy-focused teams requiring fully local observability with no external dependencies
- Teams using multiple frameworks (LlamaIndex, Haystack, DSPy) who want vendor-agnostic instrumentation
Standout features
- Local-first deployment: runs in Jupyter, locally, or via Docker with zero external dependencies
- Notebook-friendly experience designed for ML engineering workflows
- OpenInference instrumentation supports LlamaIndex, LangChain, Haystack, DSPy, smolagents
- Vendor-agnostic approach using OpenTelemetry-based standards
Pros and cons
FAQ
Q: Can Phoenix run completely locally? Yes. Phoenix can run in Jupyter notebooks, locally, or via Docker with zero external dependencies.
Q: What is OpenInference? OpenInference is an OpenTelemetry-based instrumentation standard that Phoenix uses. It enables vendor-agnostic tracing across multiple frameworks.
Q: What's the difference between Phoenix (open source) and AX (cloud)? Phoenix is the open-source, self-hosted version. AX provides managed cloud hosting with tiered limits: Free (25k spans/month), Pro, and Enterprise.
Q: Does Phoenix support cost tracking? Yes, Phoenix focuses on token-based cost tracking.
Portkey
What is Portkey?
Quick Facts:
- Type: AI Gateway / LLM Routing Framework
- Company: Portkey.ai
- Pricing: Developer free (10k logs/month); Production $49/month; Enterprise contact sales
- Open Source: Yes (MIT)
- Website: https://portkey.ai
Portkey is primarily an AI Gateway. It handles routing, fallbacks, and load balancing for LLM applications. Its lightweight architecture (~122 KB footprint) adds sub-millisecond latency overhead, making it suitable for high-performance production environments.
Observability comes as a built-in feature of the gateway rather than the primary focus. Teams often adopt Portkey to replace custom LLM management code. The unified SDKs for JavaScript and Python handle failovers, retries, and routing logic that would otherwise require significant engineering effort.
Who should use Portkey?
- Teams building production applications that need reliable routing, fallbacks, and load balancing
- Organizations with custom LLM management code they want to simplify
- Developers prioritizing gateway functionality who also want basic logging and observability
Standout features
- High-performance gateway with ~122 KB footprint and sub-millisecond latency overhead
- Automatic failovers, custom routing, retries, and load balancing
- Unified SDKs (JavaScript, Python) simplify multi-provider management
- Integration with LangChain, LlamaIndex, Autogen, and CrewAI
Pros and cons
FAQ
Q: Is Portkey primarily an observability tool or a gateway? Portkey is primarily an AI Gateway. Observability (logging, tracing) is a built-in feature but not the primary focus. Teams needing deep evaluation workflows may want to pair it with a dedicated observability platform.
Q: How much latency does Portkey add? Sub-millisecond overhead with a ~122 KB footprint.
Q: Can Portkey replace custom LLM management code? Yes. Users report removing thousands of lines of custom failover, retry, and routing code by switching to Portkey's unified SDKs.
Q: What's included in the free Developer tier? 10k logs/month, 3 days log retention, and 3 prompt templates.
Get started with LangSmith
There’s a lot of strong options to choose from for LLM observability, but the right choice depends on the problem you're solving.
If you just need to know when things break, most tools listed here will work. But if your challenge is knowing when outputs are technically correct but wrong for your domain, you need more than monitoring. You need a workflow where subject matter experts can review specific runs, rate quality, and provide context that engineers can act on.
LangSmith is built for this feedback loop. Annotation Queues let domain experts review production traces without needing engineering skills. That feedback flows directly into evaluation datasets and allows teams to optimize their ai applications.
What you get:
- Full-stack tracing that reveals the complete execution tree of any agent, regardless of framework.
- Annotation Queues where subject matter experts review, label, and correct specific traces.
- LLM-as-a-judge evaluators that automatically grade thousands of runs using your custom criteria.
- Production-to-development workflows that turn real issues into systematic improvements.
LangSmith works with your existing stack, whether that's OpenAI SDK, Anthropic, custom implementations, or any orchestration tool. No migration required.
Get a demo of LangSmith's agent engineering platform
The information provided in this article is accurate at the time of publication. Tool capabilities, pricing, and availability may change. Always verify current specifications on official websites.
AI observability requires domain experts, not just dashboards
dasdsadsaew
Most AI observability tools for agentic applications answer the question engineers ask:
"Is the system working?"
The harder question is one engineers can't answer alone:
"Is the output actually good?"
As agentic systems move from prototypes to production, observability needs to expand beyond infrastructure health. The question is no longer just whether the LLM responded, but whether the generative AI output met the standard your domain experts expect.
What is AI observability?
AI observability is the practice of collecting, analyzing, and correlating telemetry data (logs, traces, and metrics) across the full AI technology stack to understand how AI systems behave in production. It enables real-time visibility into LLMs, AI agents, orchestration layers, and their downstream impact on applications and infrastructure.
But this definition alone doesn't capture the full picture. Most definitions stop at "visibility into system behavior," which is where traditional APM left off a decade ago. The harder part, and what separates AI observability from a rebranded monitoring dashboard, is understanding whether the system is doing something useful for users. That requires a layer of insight that telemetry alone cannot provide.
The three pillars, and why they're only the starting point
AI observability inherits the three pillars from traditional software observability, each adapted for AI-specific workloads:
- Logs: Time-stamped records of application events used for troubleshooting and debugging. In AI systems, logs capture prompt submissions, model responses, tool invocations, retrieval events, and error states across multi-step agent workflows.
- Traces: End-to-end records of a request's journey through the system, from user input through orchestration, model inference, tool execution, and back. For agentic applications, traces capture the full reasoning chain, including branching decisions, retries, and intermediate outputs that shaped the final response.
- Metrics: Quantitative measures of system health over time such as latency and error rates. AI-specific metrics extend this to token consumption, inference cost, model response times, tool call latency, and feedback scores.
These three pillars give teams the vocabulary for understanding system behavior. But AI systems produce telemetry that stretches well beyond what logs, traces, and metrics were originally designed to capture. The gap between traditional observability and AI-specific observability is where most teams get stuck, and where the most AI-specific failures hide.
AI-specific telemetry: what traditional pillars miss
Token usage and cost attribution
Tokens are the fundamental unit of AI compute. Every prompt and response is broken into tokens that directly determine cost and latency. But token observability goes beyond tracking spend.
Key metrics include token consumption rates across models and inputs, and input and output tokens per trace. Teams tracking token usage at a granular level can attribute costs to specific features, users, or use cases, which makes cost optimization targeted rather than speculative.
However, token optimization solves a cost problem, not a quality problem. A team can reduce token consumption by 40% and still produce outputs that domain experts reject. This is the first hint that engineering metrics, no matter how comprehensive, address only half of the observability challenge.
Model drift
Model drift occurs when AI models gradually change behavior as the data they encounter in production diverges from the conditions they were built for. For teams using managed AI platforms, drift can also occur when providers update models without notice. A response that worked reliably last month may subtly degrade after a provider-side model update.
Key indicators include changes in response patterns over time, output quality degradation on previously reliable prompts, and shifts in latency that suggest the model is handling inputs differently. Drift is hard to catch because it's often gradual. No single response looks broken, but quality erodes over weeks.
This is where AI observability starts to demand more than dashboards. Engineers can detect drift in aggregate metrics as average response length changes, latency distributions shift, and token usage patterns evolve. But domain experts are often the first to notice output quality degrading in the specific contexts that matter most to users. A clinician notices that medication summaries are missing interaction warnings more frequently. A lawyer notices that contract analyses are citing outdated precedent. These signals arrive as anecdotes before they appear as trends, and without a structured mechanism to capture them, they get lost.
Response quality metrics
Response quality is where AI observability diverges most from traditional application monitoring. The metrics that matter include:
- Hallucination frequency across prompt types and models. Not just whether the model hallucinates, but where and how often.
- Factual accuracy, which often requires human validation or checking correctness with AI.
- Output consistency for similar inputs. Does the system produce reliable results, or does the same question yield different answers depending on phrasing?
- Relevance to user intent. Did the output actually address what the user was asking, or did it answer an adjacent question confidently?
- Latency-accuracy tradeoffs. Faster responses that sacrifice quality may look good on dashboards while frustrating users.
Most of these metrics share a common characteristic: they're difficult or impossible to evaluate fully without domain expertise. Automated scoring can approximate quality, but the ground truth for "was this output correct?" frequently lives in the minds of subject matter experts, not in a metrics pipeline.
What AI observability covers across the stack
Effective AI observability gives you end-to-end visibility across the full lifecycle of AI systems, from user input through orchestration, LLM calls, tool usage, and final output. Without this end-to-end trace, teams can troubleshoot isolated components but struggle to understand how the entire AI system behaved.
AI observability spans multiple layers of your technology stack. Each layer captures different signals, and together they form a complete picture of system behavior.
Application layer
Application-level AI observability tracks user interactions and business outcomes. This is where you measure whether AI features are actually being used, and how AI outputs connect to the metrics your business cares about, such as conversion rates, time-to-resolution, and user satisfaction.
Orchestration layer
The orchestration layer manages LLM calls, tool selection, and decision logic, whether you're using LangChain, LangGraph, or custom pipelines. Observability priorities include tracing prompt/response pairs, monitoring retries and fallback behavior, tracking tool execution timing, and understanding branching logic. When an orchestration step fails or produces unexpected results, the trace needs to show exactly which decision led to the downstream problem.
Agentic layer
The agentic layer is distinct from orchestration because it handles multi-step reasoning, autonomous workflows, memory, and goal-directed behavior. Observability priorities include tracing reasoning chains across steps, monitoring memory references and context management, tracking tool usage history and decision logs, and capturing intermediate outputs that influenced the final response.
This distinction matters because agent failures compound across steps. A flawed retrieval in step two shapes the reasoning in step five, which determines the tool call in step eight. Without agentic-layer observability, you see the final bad output but can't trace it back to the decision that caused it. This compounding effect is one of the strongest arguments for treating agents as their own observability concern.
Model and LLM layer
Model-level AI observability captures prompts, completions, token usage, latency, and associated metadata. For teams deploying multiple AI models in parallel, observability must also track which model version generated each output, how different LLM configurations compare, and where performance diverges across environments.
Working with managed AI platforms (OpenAI, Anthropic, Gemini, Bedrock, Azure AI Foundry, Vertex AI) introduces an additional challenge: model execution happens externally and opaquely. You can observe inputs and outputs, but you can't inspect what happens inside the model. This makes external observability even more critical and reinforces why domain expertise is essential. When you can't see inside the model, the quality of its outputs is the primary signal you have.
Semantic search and vector database layer
RAG components and vector databases (Pinecone, Weaviate, FAISS, Chroma, and others) form a critical layer that many observability implementations underinvest in. Observability priorities include embedding quality and consistency, retrieval relevance scores, result set sizes, query latency, and semantic drift, where the meaning of queries evolves while your embeddings remain static.
Retrieval quality is where domain expertise matters most, because only a subject matter expert can judge whether the retrieved context was actually relevant to the query. An engineer can confirm that the vector database returned five results in under 100 milliseconds. A domain expert can tell you that three of those results were from the wrong regulatory jurisdiction and the other two were outdated.
Infrastructure layer
Infrastructure observability for AI workloads extends beyond traditional APM concerns. AI-specific infrastructure considerations for companies running open source models include GPU utilization and memory pressure during inference, cost breakdowns across compute tiers, network bottlenecks for model serving (especially when calling external APIs), availability and rate limiting of managed AI endpoints, and scaling behavior under variable inference loads. Teams running AI workloads need to understand how infrastructure constraints translate to user-facing quality. A GPU memory bottleneck might force smaller context windows, which degrades output quality even though the system technically "works."
Benefits of AI observability
When implemented well, AI observability delivers measurable returns:
- Cost control: Attribute token usage and compute costs to specific requests, models, users, and features, making optimization targeted rather than across-the-board.
- End-to-end tracing: Follow a request from user input through orchestration, model inference, tool execution, and output. This is critical for debugging failures in complex agent workflows.
- Failure mode identification: Catch latency spikes, tool failures, hallucinations, degraded retrieval quality, and cascading errors before they reach users.
- Model quality assurance: Use feedback signals, correctness scores, and grounding metrics to track whether model performance is improving or regressing.
- SLA and compliance tracking: Monitor performance and reliability of AI workflows against contractual and regulatory requirements.
These benefits are real, but they address only the engineering side of the equation. Cost control doesn't tell you whether the output was worth the cost. End-to-end tracing doesn't tell you whether the trace produced a correct result. Failure identification catches system failures but misses the domain failures that erode user trust without triggering any alert.
The role of OpenTelemetry
OpenTelemetry has become the standard open-source framework for collecting and transmitting telemetry data, and its role in AI observability is growing. For teams building AI systems, OpenTelemetry offers vendor independence (avoiding lock-in to any specific observability platform) while providing end-to-end visibility across complex pipelines that span multiple models, services, and infrastructure components.
OpenTelemetry is valuable when working with managed AI platforms where model execution happens externally. It enables metadata standardization across multi-vendor AI solutions, so traces from your orchestration layer, your vector database, and your managed LLM endpoints can be correlated in a single view. For teams running heterogeneous AI stacks (and most production teams do), this interoperability matters.
The adoption gap: tracing without evaluation
As agentic applications mature, observability must account for both system health and output quality. Teams build observability around engineering metrics because that's what engineering teams can act on. Latency, error rates, and token costs are measurable, debuggable, and within the engineer's control.
But engineering metrics alone miss failures that require domain knowledge to detect, where "correct" is defined by expertise that lives outside the codebase. This gap becomes more pronounced as teams deploy AI agents that reason across multiple steps. When AI agents call tools, retrieve context, and chain LLM decisions together, quality failures compound in ways traditional monitoring cannot capture.
The below chart shows agent observability adoption for all organizations surveyed in our State of Agent Engineering survey vs. teams with production agents:
These adoption numbers show a pattern: teams have built this infrastructure. The question becomes what to do with it. High observability adoption with lower evaluation adoption (52% offline, 37% online) suggests the market has largely adopted tracing but hasn't yet linked traces to systematic quality improvements.
This reflects a broader shift across the LangChain ecosystem toward production-grade evaluation. The standard toolkit includes:
- Tracing: Capturing the complete execution tree of an agent, including tool selection, retrieved documents, parameters passed to the model at each step, and the dependencies across those components
- Monitoring dashboards: Tracking cost, latency, and error rates in real time
- Alerting: Notifying teams when metrics cross thresholds
- Usage analytics summaries: Understanding how and why users interact with AI features
These tools answer whether the API call succeeded, how long it took, and what it cost. But they don't reveal whether the output was actually useful to the user.
Why traditional engineering metrics aren't enough for AI observability
AI systems rarely fail in ways that resemble traditional software outages. Instead of crashing, LLMs confidently produce plausible but incomplete answers. Instead of throwing exceptions, AI agents may follow incorrect reasoning paths even when all traditional observability metrics appear healthy.
In these cases, existing dashboards from legacy APM providers fail to reflect true model performance. AI applications also fail in ways that latency dashboards and error rates don't capture. For example:
- A medical summary that returns in 200 milliseconds, costs exactly what you budgeted, and still misses critical clinical context that changes the diagnosis.
- A legal research tool that retrieves documents without errors while citing a precedent that was overturned three years ago.
- A financial risk report that completes successfully and passes all validation checks while using an outdated volatility model that underestimates market exposure.
In each case, every engineering metric looks healthy, yet the output is still wrong.
Domain failures produce outputs that are technically correct by engineering standards but wrong by the standards of the people who actually use them. Engineers have the systems to improve AI applications, but domain experts define what "good" means. Without a shared workspace connecting them, improvement becomes guesswork.
The below table describes a system failure versus a domain failure for agentic systems.
Many organizations have instrumented some form of observability for their agents and AI systems but haven't yet built the human feedback loops that improve agent quality over time. Observability tells you what happened. Evaluation determines whether your generative AI application is improving. For AI product and engineering teams, this shift from monitoring to measurable quality is what separates experimentation from production readiness.
Where domain feedback gets lost
In most organizations, subject-matter expert feedback flows through indirect channels. We hear this pattern repeatedly in customer conversations, e.g.:
A support engineer at a financial services company notices that a customer-facing risk report labeled a transaction as "low risk" even though the underlying analysis flagged three separate compliance concerns: unusual transaction timing, jurisdictional red flags, and a counterparty with recent regulatory scrutiny. The engineering lead files a ticket noting the inconsistency, but without structured feedback, the issue sits in a backlog alongside dozens of other ambiguous bug reports.
Meanwhile, the customer acts on the "low risk" classification, and two weeks later, the transaction triggers a regulatory inquiry. The compliance team traces the issue back to the AI-generated report, but by then, the damage is done: the inquiry costs time, money, and credibility with regulators. The AI system never crashed. Latency was fine. Token costs were within budget. But the output was wrong, and no traditional dashboard caught it.
For teams building complex AI agents, this problem compounds. A single flawed LLM decision early in a chain can propagate through downstream tool calls, yet without structured review, no one captures that failure as a training signal for the broader AI system.
Each of these moments contains a useful signal about what "good" means in that domain. But the feedback doesn't become a test case, an evaluation criterion, or a dataset for regression testing. The insight gets buried in ticket backlogs and competing priorities, replaced by new fires to fight.
The gap exists because of a team’s workflow and tooling, rather than lack of knowledge on the team. In many organizations, engineers don't have a place to send domain experts for structured review and domain experts don't have a way to provide feedback that engineering systems can consume. The result is that AI improvement relies on engineers guessing which problems matter most, and acting on whatever anecdotes happened to reach them that week.
Annotation queues as a collaboration surface
Annotation Queues provide the mechanism that connects domain expertise to engineering workflows. The concept is straightforward: production traces get routed to queues where subject matter experts can review outputs in context, add ratings, leave comments, and flag issues. The expert doesn't need to understand the trace structure or write code. They evaluate whether the output is good for their domain.
This is especially critical for teams deploying AI agents in production. As AI agents orchestrate multiple LLM calls and tools, troubleshooting shifts from fixing a single prompt to understanding how the full system behaved across steps.
Here's how the workflow operates in practice:
An engineering team configures routing rules based on criteria they care about:
- Sample 10% of all traces
- Route all traces with negative user feedback
- Send all traces for a specific use case to a specific queue
- Queues can be configured with granular access control to ensure the right experts review the right traces.
Domain experts receive notifications that traces are ready for review. They open the queue, see the actual prompt and output in context, and provide structured feedback -- a rating on a defined scale, comments explaining their reasoning, and flags for specific issues.
This transforms observability from something engineers browse alone into a shared workspace. The trace view serves as a shared visualization layer for engineers and domain experts.
- The engineer sees the full trace: every tool call, every retrieval, every step in the reasoning chain.
- The domain expert sees what matters to them: the input the user provided and the output the system returned.
- Both perspectives reside in the same place and are connected to the same underlying data.
Traditional observability shows what happened. Annotation Queues add a follow-up and help answer the question, "was it right?" That question invites domain experts, such as Product Managers, into the engineering process without requiring them to become engineers.
From feedback to evaluation criteria
When domain experts review traces and add ratings, comments, or flags, those annotations become inputs that engineering teams can use. The flagged example can flow directly into downstream workflows.
- Dataset entries: A trace marked "incorrect" with an explanation becomes a regression test case. The input-output pair links a dataset against which future model changes are evaluated. Over time, this transforms LLM observability into a structured automation pipeline in which human insight continuously informs model updates and agent behavior. It also enables AI-driven quality improvement rather than reactive debugging.
- Evaluation rubrics: Patterns in annotations show what domain experts check for. If clinicians consistently flag "missed drug interactions," that becomes an evaluation criterion that automated systems can check.
- Prompt improvement signals: Comments explain why something failed in terms that engineers couldn't have known. "This summary omits the contraindication because the source note used non-standard abbreviations," tells engineering exactly what to fix.
- Quality baselines: Aggregated ratings across hundreds of traces establish what "good" looks like quantitatively, enabling teams to measure whether changes improve or regress quality.
We see this as a development flywheel: traces flow to Insights Agent, which provides insights on common usage patterns. These insights inform dataset creation Datasets enable evaluations, evaluations drive improvements, and improvements produce new traces to observe. The flywheel relies on domain knowledge being entered into the system in a structured format. This closes the loop inside the broader AI development lifecycle, connecting production traces to iteration.
Here's what that looks like concretely: A clinician flags an output of a trace as incorrect, noting that the summary missed a drug interaction. An engineer clicks "Add to dataset." That input-output pair now runs against every prompt change. When an engineer modifies the prompt next week, the regression test catches whether the fix worked or whether it introduced new problems. The informal process of "someone mentioned this was broken, so let's try to remember to test for it" becomes a systematic quality gate.
Compliance, audit trails, and regulatory readiness
AI observability plays a direct role in compliance, and this is only becoming more true. The EU AI Act imposes transparency and documentation requirements on high-risk AI systems, and emerging US state regulations are following suit with mandates for explainability and auditability in AI decision-making.
For teams in regulated industries, end-to-end traceability is a compliance requirement, rather than just a debugging convenience. Every LLM decision, tool invocation, and retrieved document needs to be auditable. PII detection and protection is itself an observability concern. Teams need to monitor whether sensitive data is being passed through AI pipelines and whether outputs inadvertently expose protected information.
Compliance in healthcare, legal, and financial services often requires demonstrating that domain-qualified humans reviewed AI outputs: that a clinician validated the medical summary, that an attorney reviewed the contract analysis, that a compliance officer signed off on the risk assessment. Structured annotation workflows both improve quality and create the audit trail that regulators expect. The annotation itself becomes evidence that human oversight occurred, who reviewed it, what they found, and when.
Collaborative workflow in practice
For teams in healthcare, legal, finance, and enterprise B2B, routing production traces to expert-review queues links domain knowledge to product improvements in a repeatable way. The pattern looks similar across domains, even when the specific expertise differs.
If you're building in healthcare, you might route patient-facing summaries to a queue accessible to clinical reviewers. Your reviewers (nurses, physicians, or clinical informaticists) evaluate whether the summaries capture medically relevant information and flag cases where context is missed or language confuses patients. They identify which failure modes occur most frequently and prioritize fixes based on clinical impact rather than engineering convenience.
If you're building legal tools, you might have attorneys review the outputs of contract analysis. They know which clauses matter, which precedents are current, and which jurisdictional nuances the model misses. Their annotations become test cases that catch regressions before they reach clients.
For legal and financial AI agents, end-to-end traceability ensures that every LLM decision and tool invocation can be reviewed in context, which is essential when troubleshooting high-stakes outputs.
If you're building financial applications, you might route forecasting explanations to analysts who validate the reasoning. They know when a model is confusing correlation with causation, when it's extrapolating beyond reasonable bounds, or when its confidence should be lower given market conditions.
This approach requires organizational buy-in. Subject matter experts need time allocated for review, which adds to their workload. Engineering needs to build the routing rules and close the loop by actually using the feedback. There is a tradeoff for this. The payoff is that "the AI isn't good enough" becomes a set of specific issues you can fix and measure.
Tradeoffs and when this fits
While Annotation Queues enable domain experts to review production AI outputs, manual annotation doesn't scale to every trace. With agents producing millions of traces per day, reviewing everything manually is impossible. Teams need sampling strategies: route a percentage of all traces, prioritize traces with negative signals, or focus expert review on high-stakes use cases while letting automated evaluation handle routine cases. The goal is to maximize the signal-to-noise ratio: get domain experts looking at the traces where their judgment matters most, rather than asking them to review outputs that automated systems can already evaluate reliably.
Subject matter expert time is expensive and limited. Clinicians, lawyers, product managers, and analysts have primary responsibilities that don't include reviewing AI outputs. The annotation workflow competes for their attention. Teams that succeed typically start small, demonstrate value quickly, and expand review coverage as they prove the feedback loop works.
The feedback loop is slower than automated evaluation. An automated eval can score every trace in real time. Human annotation takes hours or days, depending on queue depth and reviewer availability. For rapid iteration cycles, human review supplements automated evaluation rather than replacing it.
The decision comes down to the quality signal you need. Automated evaluation works well when you can encode "good" in a prompt or heuristic. Human review becomes essential when "good" requires expertise you can't encode, when the cost of being wrong is high, or when you're still learning what failure modes exist.
Leveraging Annotation Queue works when:
- Domain correctness matters more than speed of iteration
- The cost of being wrong is high (regulated industries, medical decisions, legal advice)
- Automated evaluation can't capture what "good" means because "good" requires expertise you can't encode in a prompt
- You have accessible domain experts who can dedicate some time to reviewing
- You're building for users who will notice and care about domain-specific quality
Annotation Queues aren’t as strong of a fit for situations when:
- You're in a rapid prototyping phase where the product is changing faster than review cycles
- The domain is general enough that automated evaluation handles most quality concerns
- You don't have subject matter experts available, or you can't allocate their time
Annotation Queues bridge the gap between what engineers can measure and what domain experts can judge. Traditional observability tells you the system is running: traces are complete, latency is acceptable, no errors are thrown. But it can't tell you whether the output was right for your domain. That requires human judgment from people who understand regulatory requirements, company policies, clinical standards, or legal precedent.
By routing production traces to subject matter experts for structured review, annotation queues transform observability from a reactive debugging tool into an active quality improvement system. The compliance officer who spots a policy violation, the clinician who catches a missed contraindication, and the analyst who identifies flawed reasoning all contribute expertise that becomes embedded in your evaluation pipeline. This structured feedback replaces ad hoc Slack messages and ticket backlogs with actionable data.
This is the difference between knowing your agent ran and knowing it worked. Engineering instrumentation shows you what happened. Domain expertise tells you whether it should have happened that way. Annotation queues connect the two, turning expert judgment into dataset entries, evaluation criteria, and regression tests that make your AI systematically better at the things that actually matter to your users.
Making AI observability work harder
Most teams treat AI observability as an engineering debugging tool. The real opportunity lies in turning those traces into a quality improvement system. Traces and production data are already flowing through your systems. The missing piece is a mechanism that enables people who know what "good" means to contribute that knowledge in a structured way.
In practice, AI observability becomes the backbone of sustainable improvement across releases. For teams in specialized domains where the hardest failures are domain-level rather than system-level, this workflow turns observability into a feedback loop. The next step is practical. Identify one use case where domain expertise matters more than engineering intuition. Set up a queue. Route a sample of traces. Get one expert reviewing for one week. Watch what they flag.
If the feedback reveals failure modes you didn't know existed, you've found the place where observability becomes collaboration, and where improvement is based on what "good" actually means in your domain.